

n8n 2.0: Das Hardening Release, das wir brauchten
n8n 2.0 ist am 8. Dezember 2024 erschienen, und es ist die Art von Release, über die sich zunächst niemand so richtig freut, die aber jeder irgendwann zu

In den vorangegangenen Teilen (Teil 1 und Teil 2) dieser Blogserie haben wir uns mit Herausforderungen beschäftigt, vor denen DevOps heute steht, wie KI diese lösen kann und wie man mit Frameworks wie LangChain leistungsstarke KI-Anwendungen erstellt. In diesem letzten Teil befassen wir uns nun mit den Infrastrukturoptionen für das Hosting von KI-Anwendungen, der Optimierung ihrer Leistung, Generation Guardrails für eine sichere Interaktion und der Verwendung von KI-Agents zur Automatisierung von komplexen Workflows.
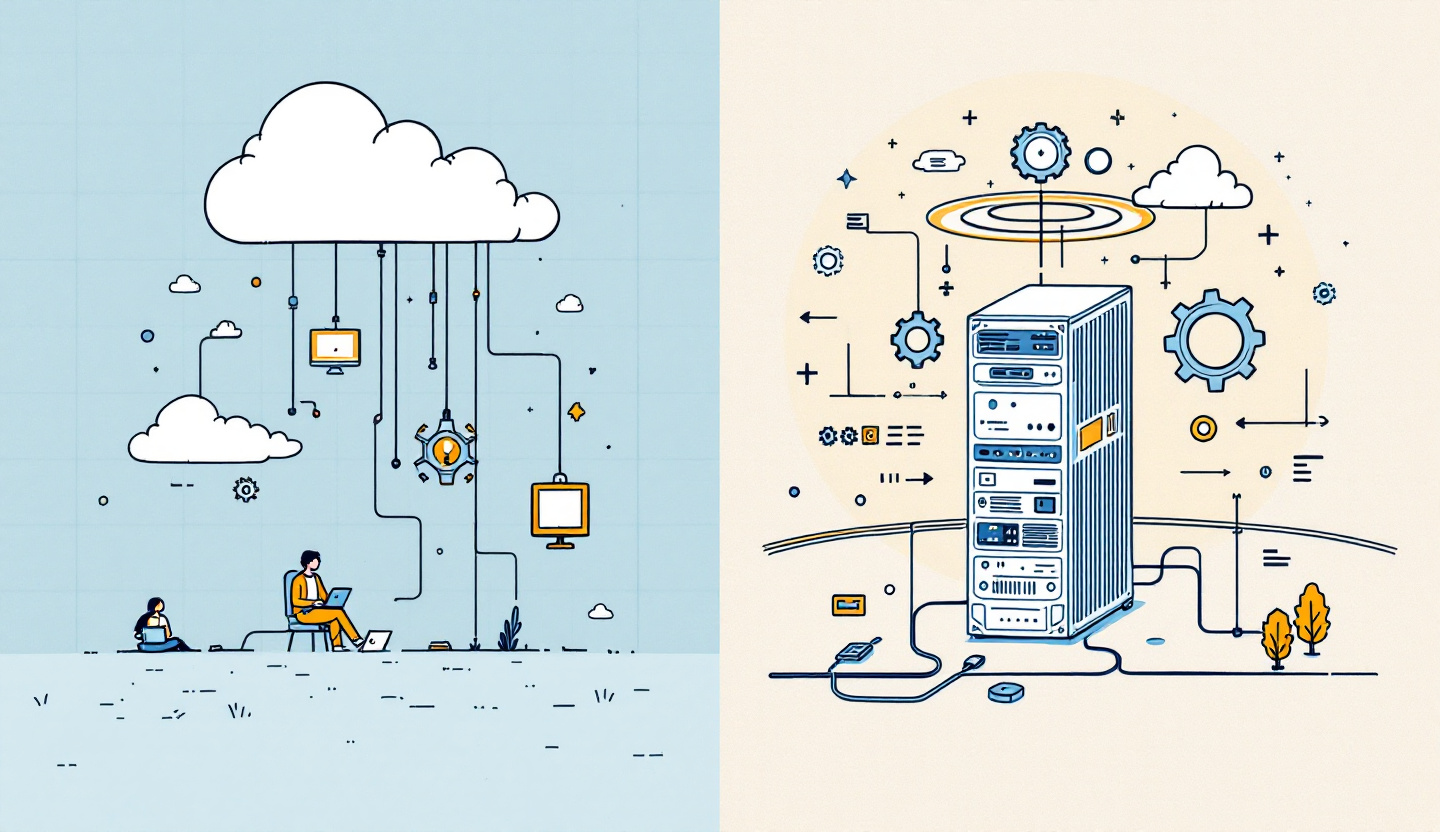
Beim Einsatz von KI-Anwendungen ist eine der ersten Entscheidungen die Wahl der Hosting-Option für unser Sprachmodell. Es gibt zwei Hauptansätze: cloud-basierte und selbstgehostete Modelle.
Cloud-basierte Modelle werden von Unternehmen wie OpenAI, Anthropic, Azure AI und noch mehr Cloud-Anbietern bereitgestellt. Diese Dienste sind vor allem wegen ihrer Benutzerfreundlichkeit und Skalierbarkeit beliebt.
Beim Self-Hosting wird das Modell mit Hilfe von Tools wie Ollama, Llama.cpp oder LM Studio auf der eigenen Infrastruktur ausgeführt.
Die Inferenzgeschwindigkeit gibt an, wie schnell ein Modell Reaktionen verarbeitet und erzeugt. Dies wird von mehreren Faktoren beeinflusst:
Wenn die Anwendung unterschiedliche Modelle für verschiedene Aufgaben benötigt, kann die Sprachmodell-Proxysuche helfen. Diese Technik leitet Anfragen auf der Grundlage vordefinierter Faktoren oder Aufgaben intelligent an bestimmte Modelle weiter.
LiteLLM ist ein Open-Source-Framework, das die Arbeit mit mehreren Sprachmodellen vereinfachen soll. Es bietet eine standardisierte API zum Aufrufen von über 100 verschiedenen LLMs, wie OpenAI, Anthropic, Google Gemini und Hugging Face.
Im Folgenden wird erläutert, wie LiteLLM zur Verwaltung mehrerer LLMs in einer einzigen Anwendung eingesetzt werden kann:
1import streamlit as st
2from litellm import completion
3
4st.title("Multi-Model Chat")
5
6# LiteLLM Completion function to get model response
7def get_model_response(model_name: str, prompt: str) -> str:
8 response = completion(model=model_name, messages=[{"role": "user", "content": prompt}])
9 return response.choices[0].message.content
10
11# Streamlit UI Selection for model
12model_option = st.selectbox("Choose a language model:", ("gpt-3.5-turbo", "ollama/llama2", "gpt-4o"))
13
14# Chat history session state
15if 'chat_history' not in st.session_state:
16 st.session_state['chat_history'] = []
17
18user_input = st.text_input("You:")
19
20# Send user input and get model response
21if st.button("Send") and user_input:
22 st.session_state['chat_history'].append({"role": "user", "content": user_input})
23 with st.spinner("Thinking..."):
24 response = get_model_response(model_name=model_option, prompt=user_input)
25 st.session_state['chat_history'].append({"role": "model", "content": response})
26
27for message in reversed(st.session_state['chat_history']):
28 st.write(f"{message['role'].capitalize()}: {message['content']}")
In diesem Beispiel erstellen wir eine einfache Chat-Anwendung, bei der die Anwender aus verschiedenen Sprachmodellen wählen können. Die Funktion get_model_response sendet die Benutzereingabe an das ausgewählte Modell und gibt die Antwort zurück. Der Sitzungsstatus chat_history speichert den Gesprächsverlauf, und die Streamlit-Schnittstelle zeigt die Chat-Nachrichten in einer interaktiven Web-UI an.

Sobald unsere KI-Anwendung läuft, ist die Überwachung ihrer Leistung entscheidend, um Zuverlässigkeit und Effizienz zu gewährleisten.
Wir können KI-gestützte Tools wie Grafana oder BigPanda für eine effektive Überwachung und Analyse einsetzen.
Die Durchführung von LLM-Bewerbungen kann kostspielig sein, daher ist es wichtig, die Kosten zu kennen und zu verwalten.

Öffentlich zugängliche LLM-Anwendungen sind mit besonderen Sicherheitsanforderungen verbunden.
KI-Agents sind mehr als nur Texterzeuger - sie führen eigenständig Aufgaben aus und ermöglichen komplexe, mehrstufige Arbeitsabläufe. Lasst uns die wichtigsten Merkmale dieser Agenten erkunden und wie man sie entwickelt.
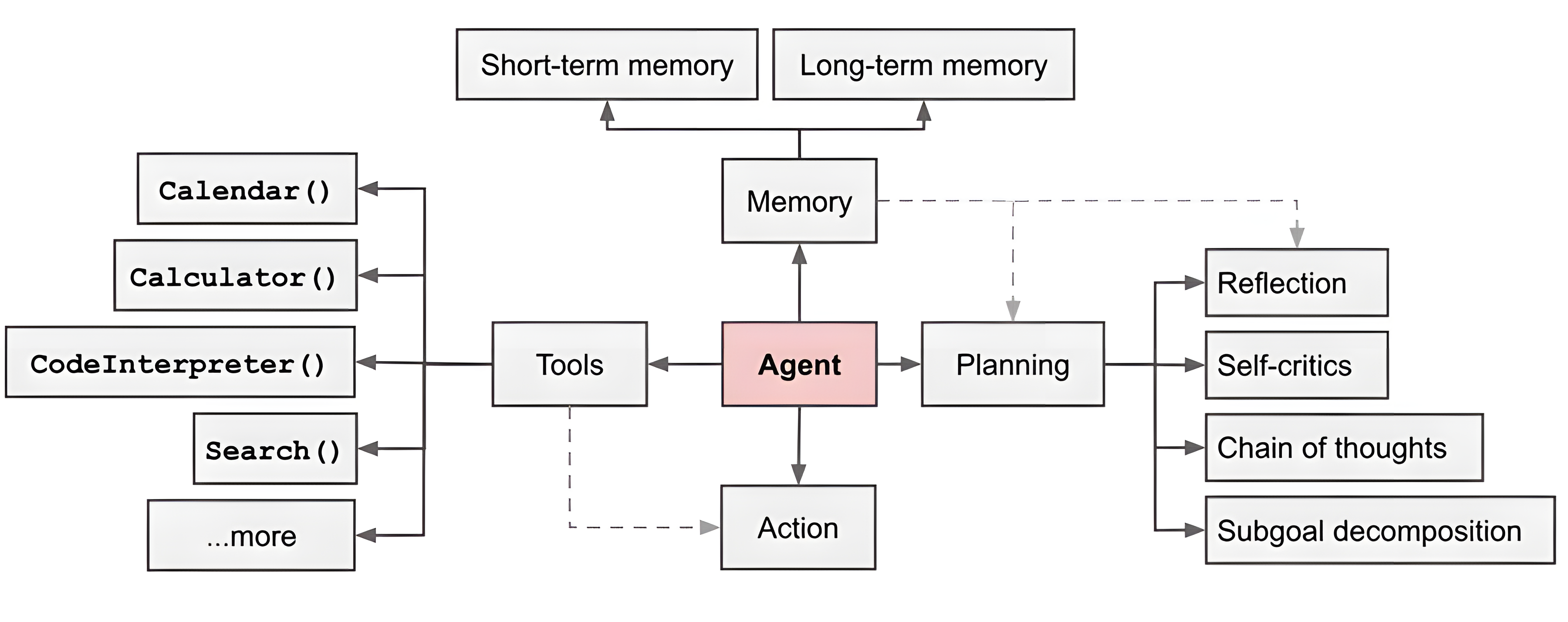
Ein KI-Agent besteht aus mehreren Komponenten, die zusammenarbeiten, um Aufgaben effektiv zu erfüllen:
LangGraph ist ebenfalls eine Komponente des LangChain-Ökosystems, die eine "visuelle" Schnittstelle für die Gestaltung und Verwaltung von Agent-Workflows bietet. Sie vereinfacht den Prozess der Verbindung verschiedener Komponenten und der Orchestrierung komplexer Aufgaben.
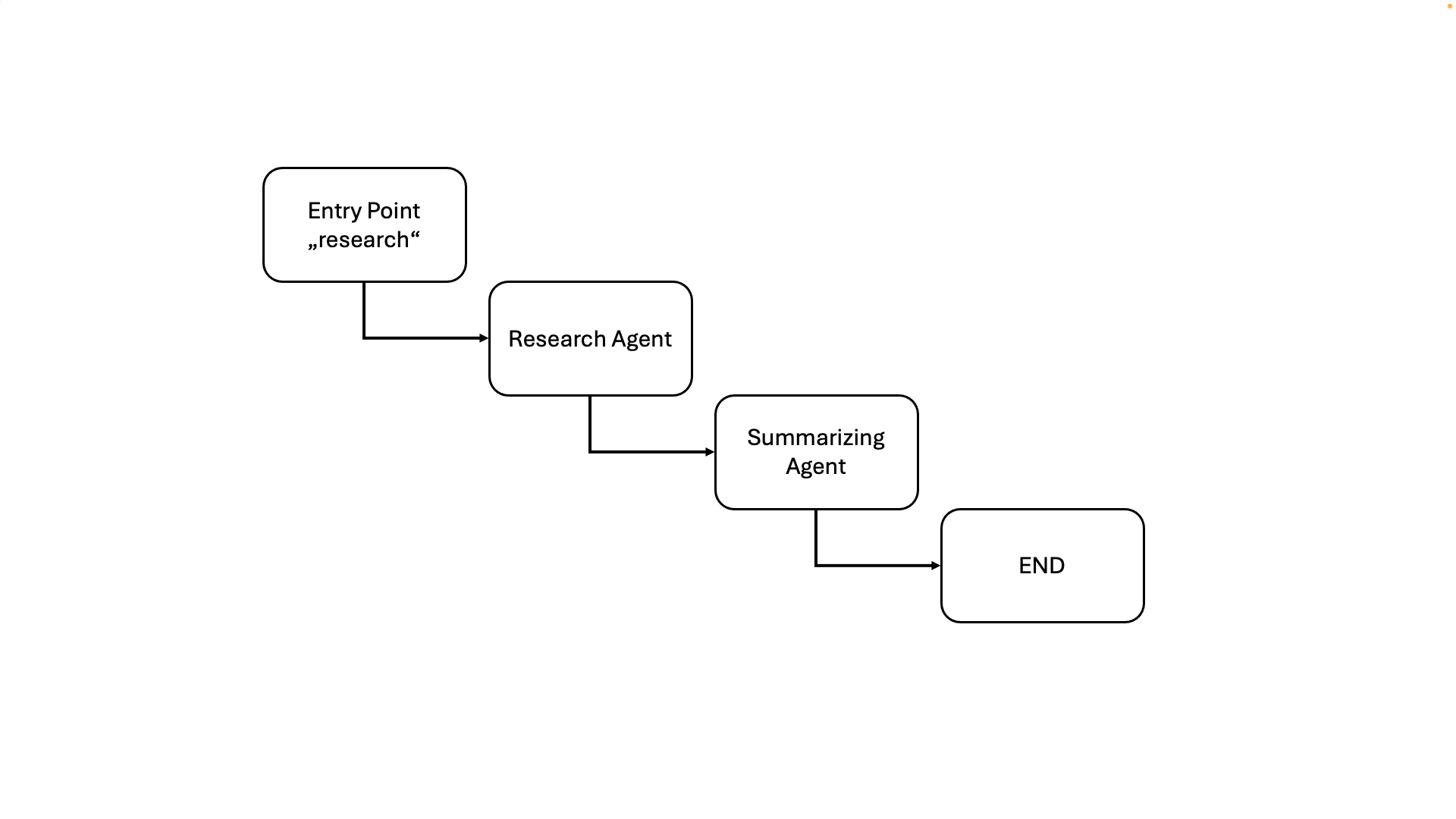
Dieser Agent führt eine Web-Recherche durch und fasst die Ergebnisse zusammen.
1from langchain.chat_models import ChatOpenAI
2from langchain.tools import DuckDuckGoSearchRun
3from langgraph.graph import StateGraph, END
4from typing import TypedDict, Annotated, List
5import operator
6
7# Initialize models and tools
8research_model = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.7)
9summary_model = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.3)
10search_tool = DuckDuckGoSearchRun()
11
12# Define graph state structure
13class ResearchState(TypedDict):
14 query: str
15 research_results: Annotated[List[str], operator.add]
16 summary: str
17
18graph = StateGraph(ResearchState)
19
20# Define agent functions
21def research_agent(state):
22 query = state["query"]
23 search_result = search_tool.run(query)
24 return {"research_results": [search_result]}
25
26def summarization_agent(state):
27 research_results = state["research_results"]
28 summary_prompt = f"Summarize the following research results:\n{research_results}"
29 summary = summary_model.predict(summary_prompt)
30 return {"summary": summary}
31
32# Build the graph
33graph.add_node("research", research_agent)
34graph.add_node("summarize", summarization_agent)
35graph.set_entry_point("research")
36graph.add_edge("research", "summarize")
37graph.add_edge("summarize", END)
38
39# Compile and run
40app = graph.compile()
41
42def run_research(query):
43 result = app.invoke({"query": query, "research_results": [], "summary": ""})
44 return result["summary"]
45
46# Example usage
47research_topic = "Latest advancements in AI"
48summary = run_research(research_topic)
49print(f"Research Summary on '{research_topic}':\n{summary}")
In diesem Beispiel definieren wir einen Forschungsagent, der eine Websuche zu einem bestimmten Thema durchführt und die Ergebnisse zusammenfasst. Der Agent verwendet LangGraph, um einen Zustandsautomaten zu erstellen, der den Arbeitsablauf durch die Recherche- und Zusammenfassungsschritte leitet. Die Funktion run_research initiiert den Agent mit einer Suchanfrage und liefert die endgültige Zusammenfassung.
So würde die visuelle Darstellung dieses einfachen Arbeitsablaufs aussehen:
In diesem letzten Teil unserer Blogserie haben wir die kritischen Aspekte der Bereitstellung und Verwaltung von KI-Anwendungen für DevOps-Engineers untersucht. Von Hosting-Optionen und Leistungsoptimierung bis hin zu Überwachung, Kostenmanagement und Sicherheit haben wir die wesentlichen Überlegungen zum Aufbau zuverlässiger und effizienter KI-gestützter Systeme behandelt. Außerdem haben wir über KI-Agents gesprochen und ihre Fähigkeit zur Automatisierung komplexer Workflows und zur Anpassung an dynamische Umgebungen vorgestellt.
In dieser Blogserie wurde untersucht, wie KI DevOps verändert, von der Bewältigung von Herausforderungen bis hin zur Erstellung und Bereitstellung von fortschrittlichen KI-Anwendungen. Lasst uns kurz die wichtigsten Erkenntnisse zusammenfassen:
Danke, dass Sie uns auf dieser Reise begleiten! Bleiben Sie neugierig und zögern Sie nicht, sich bei Fragen oder Anregungen an uns zu wenden.
Wenn Sie noch mehr erfahren möchten, sehen Sie sich unbedingt unsere Videos unseres neuesten KI-Workshops für DevOps-Engineers auf YouTube an:
n8n 2.0 ist am 8. Dezember 2024 erschienen, und es ist die Art von Release, über die sich zunächst niemand so richtig freut, die aber jeder irgendwann zu
In den acht Monaten seit unserem letzten Bericht über das Mondoo March 2025 Release ist viel passiert. Wenn ihr die Plattform bereits nutzt, habt ihr
Das Problem: Fest codierte Zugangsdaten Jeder Entwickler hat diese Versuchung schon erlebt: Sie müssen schnell etwas testen, also codieren Sie einen
Wie Claude Sonnet 4.5 und GitHub Copilot uns durch das Labyrinth von Custom-Backstage-Integrationen geholfen haben Das Backstage-Versprechen (und die Realität)
Kurzer Read (~6–7 Min) – fokussiert auf den operativen Teil der Model Context Protocol (MCP) Enablement. 1. Praxisproblem Ein einzelner MCP-Server ist trivial.
Sie interessieren sich für unsere Trainings oder haben einfach eine Frage, die beantwortet werden muss? Sie können uns jederzeit kontaktieren! Wir werden unser Bestes tun, um alle Ihre Fragen zu beantworten.
Hier kontaktieren