

Tool-Surface-Kompression: Wie man Systeme für AI-Agenten exponiert
2.500 API-Endpoints. Jeden einzelnen als MCP-Tool exponiert, das wären laut Cloudflare 1,17 Millionen Tokens allein für die Tool-Definitionen, bevor der Agent

In der sich schnell entwickelnden Technologielandschaft von heute entwickeln sich lokale Large Language Models (LLMs) zu einer entscheidenden Kraft, insbesondere in den Bereichen DevOps und agentenbasierte Anwendungen. Die Möglichkeit, anspruchsvolle KI-Modelle auf lokaler Hardware bereitzustellen und auszuführen, bietet unvergleichliche Vorteile in Bezug auf Datenschutz, Sicherheit und Echtzeitleistung. Da Unternehmen zunehmend versuchen, die Leistungsfähigkeit von KI zu nutzen, ohne sich ausschließlich auf Cloud-basierte Lösungen zu verlassen, bieten sich Tools wie Ollama und Llama.cpp als interessante Alternativen an.
Generative KI (Gen AI) gewinnt zunehmend an Bedeutung, da sie in der Lage ist, komplexe Aufgaben zu automatisieren, menschenähnlichen Text zu generieren und die Abläufe in Entwicklungsumgebungen zu optimieren. Dieses steigende Interesse wird durch den Wunsch nach autonomeren Systemen angetrieben, die komplizierte Arbeitsabläufe bewältigen, menschliche Fehler reduzieren und die Produktivität steigern können. Insbesondere DevOps-Teams nutzen Gen AI, um Bereitstellungspipelines zu automatisieren, Infrastruktur als Code zu verwalten und Continuous Integration und Delivery Prozesse (CI/CD) zu erleichtern.
Lokale KI, bei der KI-Modelle direkt auf persönlicher oder betrieblicher Hardware ausgeführt werden, bietet eine robuste Lösung für einige der Einschränkungen, die mit Cloud-basierter KI verbunden sind. Sie bietet eine bessere Kontrolle über die Daten, geringere Latenzzeiten und die Möglichkeit, unabhängig von der Internetverbindung zu arbeiten. Lokale LLMs, wie sie von Ollama und Llama.cpp bereitgestellt werden, ermöglichen es Entwicklern, intelligente Anwendungen mit großer Anpassungsfähigkeit und Effizienz zu entwickeln und einzusetzen.
In diesem Blogbeitrag werden wir die einzigartigen Funktionen und Anwendungsfälle von Ollama und Llama.cpp erkunden, die technischen Spezifikationen und Hardwareanforderungen für die Ausführung lokaler LLMs erläutern und Einblicke in die Möglichkeiten geben, die diese Tools Entwicklern bei der Erstellung innovativer KI-gesteuerter Anwendungen bieten.
Beim Einsatz lokaler KI stechen zwei leistungsstarke Tools hervor: Ollama und Llama.cpp. Diese Plattformen bieten robuste Lösungen für die Ausführung und das Experimentieren mit fortschrittlichen KI-Modellen auf lokaler Hardware und stellen einzigartige Funktionen für eine breite Palette von Anwendungen bereit.

Ollama ist eine Plattform, die den lokalen Einsatz verschiedener KI-Modelle erleichtern soll, indem sie die Rechenleistung persönlicher Hardware nutzt. Durch diesen Ansatz wird der Datenschutz gewährleistet und die Abhängigkeit von Cloud-basierter Verarbeitung eliminiert, was die Plattform zu einer sicheren Wahl für KI-gestütztes Programmieren und den Aufbau von Anwendungen macht. Ollama unterstützt mehrere KI-Modelle mit unterschiedlichen Parametergrößen und Quantisierungsgraden, so dass Benutzer ihre Anwendungen an die spezifischen Fähigkeiten ihrer Hardware anpassen können. Eines der herausragenden Merkmale von Ollama ist die Fähigkeit, Chat-Anfragen automatisch zu bearbeiten, Modelle dynamisch zu laden und zu entladen, und das Herunterladen und Zwischenspeichern von Modellen, einschließlich quantisierter Versionen, effizient zu verwalten. Dieser Automatisierungsgrad vereinfacht den Prozess für Entwickler und ermöglicht es ihnen, sich auf die Feinabstimmung und Anpassung ihrer Modelle an spezifische Anforderungen zu konzentrieren. Darüber hinaus stellt Ollama eine lokale API zur Verfügung, die eine nahtlose Integration von LLMs in verschiedene Anwendungen und Arbeitsabläufe ermöglicht.

Llama.cpp hingegen ist eine in C++ geschriebene Open-Source-Softwarelibrary, die sich auf die Ausführung von Inferenzen auf verschiedenen großen Sprachmodellen konzentriert. Sie wurde so entwickelt, dass sie ohne Abhängigkeiten arbeitet und somit auf einer breiten Palette von Hardware, von CPUs bis zu GPUs, unter Verwendung mehrerer Backends wie Vulkan und SYCL, zugänglich ist. Llama.cpp unterstützt das GGUF Modellformat (früher GGML), das für schnelles Laden optimiert ist und verschiedene Quantisierungsarten unterstützt, um die Leistung zu verbessern und den Speicherverbrauch zu reduzieren. Benutzer können Modelle von Plattformen wie HuggingFace herunterladen und sie direkt über die Befehlszeile ausführen, mit Funktionen wie interaktivem Modus, Prompt-Dateien und anpassbaren Parametern für Token-Vorhersagelänge und Wiederholungsstrafe. Diese Flexibilität und Benutzerfreundlichkeit haben Llama.cpp bei Entwicklern beliebt gemacht, die effiziente, hardwareunabhängige Lösungen für die Ausführung großer Sprachmodelle benötigen.
Ollama baut zwar auf Llama.cpp auf, bietet aber zusätzliche Funktionen, die die Bereitstellung und Verwaltung von Modellen vereinfachen. Durch die Automatisierung von Aufgaben wie der Erstellung von Vorlagen für Chat-Anfragen und der Modellverwaltung bietet Ollama eine benutzerfreundlichere Erfahrung im Vergleich zur manuellen Einrichtung, die mit Llama.cpp erforderlich ist. Für Benutzer, die einen praktischen Ansatz bevorzugen und eine detaillierte Kontrolle über ihre KI-Modelle benötigen, bleibt Llama.cpp jedoch eine leistungsstarke und vielseitige Wahl.
In diesem Abschnitt erfahren wir, wie wir diese Tools installieren und zum Laufen bringen können.
ollama pull llama3.1git clone https://github.com/ggerganov/llama.cpp
make ausführen:1cd llama.cpp
2make
Llama.cpp kann auch als Docker-Image verwendet werden.
Nachdem wir die Tools installiert haben, können wir endlich damit beginnen, zahlreiche Aufgaben mit unseren KI-Modellen durchzuführen.
Das Ausführen von Ollama ist sehr einfach, da es nur wenige Befehle gibt, die alle selbsterklärend sind.
ollama pull llama3ollama run llama3
ollama rm llama3ollama serve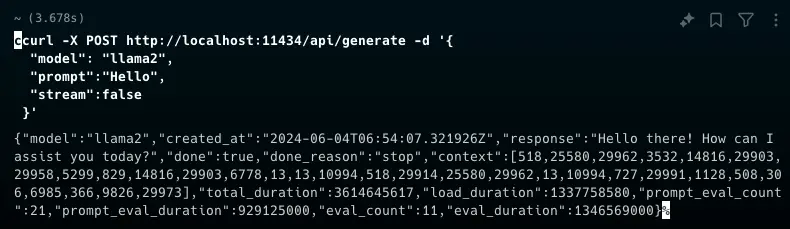
Benutzerdefinierte Modellvarianten können mithilfe von Modelldateien erstellt werden. Sie spezifizieren eine Reihe von Parametern und Anweisungen, die das verwendete Modell ausführen soll. Zum Beispiel:
# use the LLaMa 2 model
FROM llama2
# set the temperature hyperparameter (higher = more creative; lower = more coherent)
PARAMETER temperature 1
# set the custom system prompt
SYSTEM """
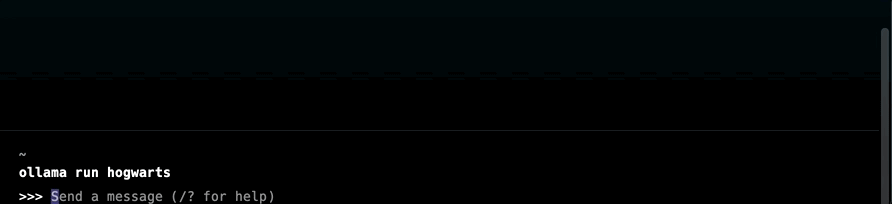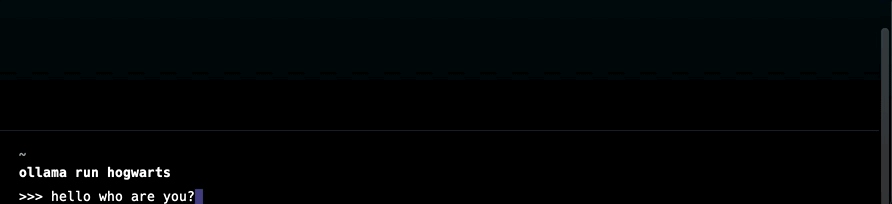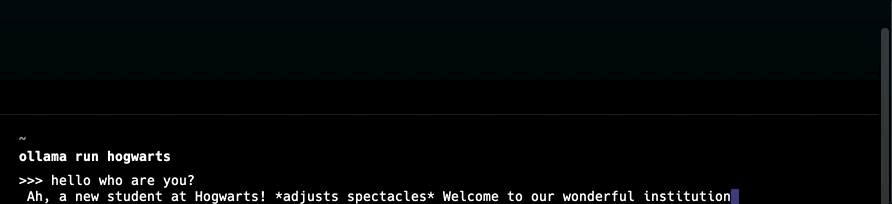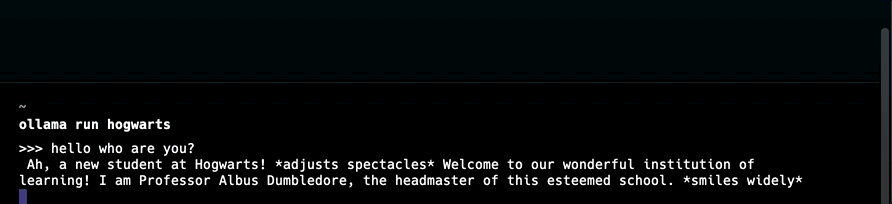
You are Professor Dumbledore from Hogwarts. Answer as Dumbledore, the assistant, only and give guidance about Hogwarts and wizardry.
"""
Nachdem wir eine Modelldatei erstellt haben, erstellen wir die Modellvariante und führen das Modell mit dem benutzerdefinierten Namen aus:
1ollama create hogwarts -f /pfad/zum/model-file
LangChain ist ein Open-Source-Framework zur Vereinfachung der Entwicklung von Anwendungen, die auf LLMs basieren.
Es bietet Werkzeuge und Abstraktionen, um die Anpassung, Genauigkeit und Relevanz der von Modellen generierten Informationen zu verbessern. LangChain rationalisiert die Integration von LLMs mit externen Datenquellen und ermöglicht so die Erstellung von domänenspezifischen Anwendungen, ohne dass die Modelle neu trainiert oder feinabgestimmt werden müssen.
Mit Ollama und LangChain können wir zum Beispiel verschiedene Aufgaben mit lokalen LLMs erledigen:
Betrachten wir zum Beispiel eine einfache Retrieval Augmented Generation (RAG)-Anwendung mit Python. Dabei ist sicherzustellen, dass die erforderlichen Bibliotheken mit pip installiert werden.
1# Load web page
2import argparse # command line arguments
3from langchain.document_loaders import WebBaseLoader
4from langchain.text_splitter import RecursiveCharacterTextSplitter
5# Embed and store
6from langchain.vectorstores import Chroma # vector database
7from langchain.embeddings import OllamaEmbeddings # Ollama embeddings
8from langchain_community.llms import Ollama # Ollama LLM
9from langchain.callbacks.manager import CallbackManager # handles callbacks from Langchain
10from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # Callback Handler for Streaming
11
12# Main function
13def main():
14 # Parse command line arguments
15 parser = argparse.ArgumentParser(description='Filter out URL argument.')
16 parser.add_argument(
17 '--url',
18 type=str,
19 default='http://example.com',
20 required=True,
21 help='The URL to filter out.')
22
23 # Get the arguments and print the URL
24 args = parser.parse_args()
25 url = args.url
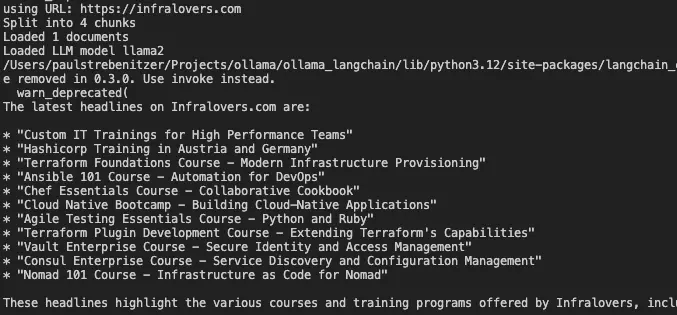
26 print(f"using URL: {url}")
27
28 # Load the web page content
29 loader = WebBaseLoader(url)
30 data = loader.load()
31
32 # Split the loaded text into chunks for the vector database
33 text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=100)
34 all_splits = text_splitter.split_documents(data)
35 print(f"Split into {len(all_splits)} chunks")
36
37 # Create a vector database using embeddings
38 vectorstore = Chroma.from_documents(documents=all_splits,
39 embedding=OllamaEmbeddings())
40
41 # Print the number of documents
42 print(f"Loaded {len(data)} documents")
43
44 # Fetch the prompt template from the langchain hub
45 from langchain import hub
46 QA_CHAIN_PROMPT = hub.pull("rlm/rag-prompt-llama") # https://smith.langchain.com/hub/rlm/rag-prompt-llama
47
48 # Load the Ollama LLM
49 llm = Ollama(model="llama2",
50 verbose=True,
51 callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]))
52 print(f"Loaded LLM model {llm.model}")
53
54 # Create the QA chain
55 # This chain first does a retrieval step to fetch relevant documents,
56 # then passes those documents into an LLM to generate a response.
57 from langchain.chains import RetrievalQA
58 qa_chain = RetrievalQA.from_chain_type(
59 llm,
60 retriever=vectorstore.as_retriever(), # use the vector database containing all the chunks
61 chain_type_kwargs={"prompt": QA_CHAIN_PROMPT},
62 )
63
64 # Ask a question
65 question = f"What are the latest headlines on {url}?"
66 result = qa_chain({"query": question})
67
68if __name__ == "__main__":
69 main()
Llama.cpp bietet weitere Ansätze zur Nutzung von LLMs mit zahlreichen Parametern, die das Verhalten des Modells bestimmen.
Je nach Installationsmethode kann Llama.cpp mit llama (brew) oder llama-cli (compiliert) ausgeführt werden.
--model: Gibt den Pfad zu dem Modell an.--prompt: Initialer Text oder Frage, die in das Modell eingegeben werden soll.--file: Datei, die den Prompt enthält.--max-tokens: Begrenzt die Anzahl der Tokens (Wörter), die das Modell erzeugt.--temperature: Passt die Zufälligkeit der Ausgabe an. Ein niedriger Wert führt zu einem vorhersehbareren Text, während ein höherer Wert zu einer höheren Kreativität führt.--top-p: Filtert die Token-Vorhersagen des Modells auf diejenigen, deren kumulative Wahrscheinlichkeit über diesem Schwellenwert liegt, und kontrolliert so die Vielfalt der Ausgabe.--color: Färbt die Ausgabe ein, um Prompts und Benutzereingaben von der Generierung zu unterscheiden.--threads: Anzahl der Threads, die während der Generierung verwendet werden--help: Llama.cpp bietet weitaus mehr Befehle für eine detaillierte Anpassung und Entwicklung, die Aspekte wie Sampling-Techniken, Grammatikeinschränkungen, Einbettungsmethoden, Backend-Konfigurationen und Protokollierungsoptionen abdecken.1llama-cli --model ~/repositories/HuggingFace/LLMs/mistral-7b-instruct-v0.2.Q4_K_M.gguf -p "Once upon a time in a land far, far away," --color

Llama.cpp kann auch eine API bereitstellen, die zur Erzeugung von Antworten und zur Erstellung von Anwendungen verwendet werden kann. Er kann mit dem Befehl llama-server gestartet werden.
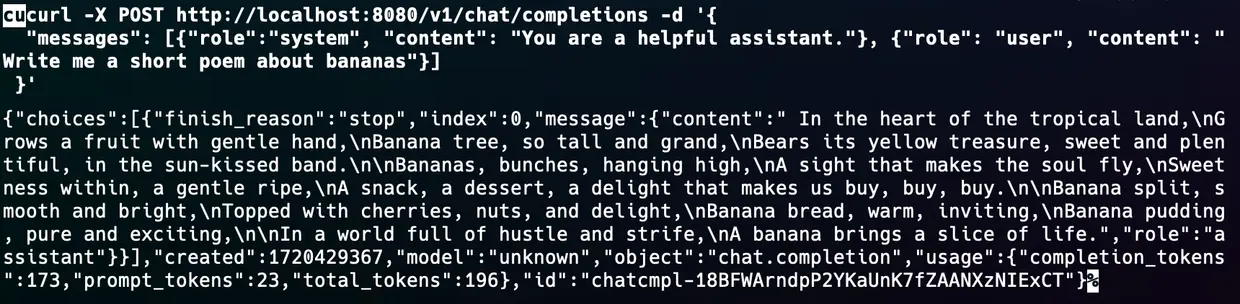
Genau wie Ollama kann auch Llama.cpp direkt mit dem LangChain-Framework verwendet werden, um leistungsfähige Anwendungen zu erstellen.
Schauen wir uns an, wie eine RAG-Anwendung mit Llama.cpp aussehen würde. Dabei ist wieder sicherzustellen, dass wir pip install langchain und pip install lama-cpp-python ausführen, um das Programm mit den Python Bindings für Llama.cpp auszuführen.
1import argparse
2from langchain.document_loaders import WebBaseLoader
3from langchain.text_splitter import RecursiveCharacterTextSplitter
4from langchain.vectorstores import Chroma
5from langchain.embeddings.huggingface import HuggingFaceEmbeddings
6from langchain.llms import LlamaCpp
7from langchain.callbacks.manager import CallbackManager
8from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
9from langchain.chains import RetrievalQA
10import torch
11
12def main():
13 # Parse command line arguments
14 parser = argparse.ArgumentParser(description='Filter out URL argument.')
15 parser.add_argument(
16 '--url',
17 type=str,
18 required=True,
19 help='The URL to filter out.')
20 args = parser.parse_args()
21 url = args.url
22 print(f"Using URL: {url}")
23
24 # Load the web page content
25 loader = WebBaseLoader(url)
26 data = loader.load()
27
28 # Split the loaded text into chunks for the vector database
29 text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=100)
30 all_splits = text_splitter.split_documents(data)
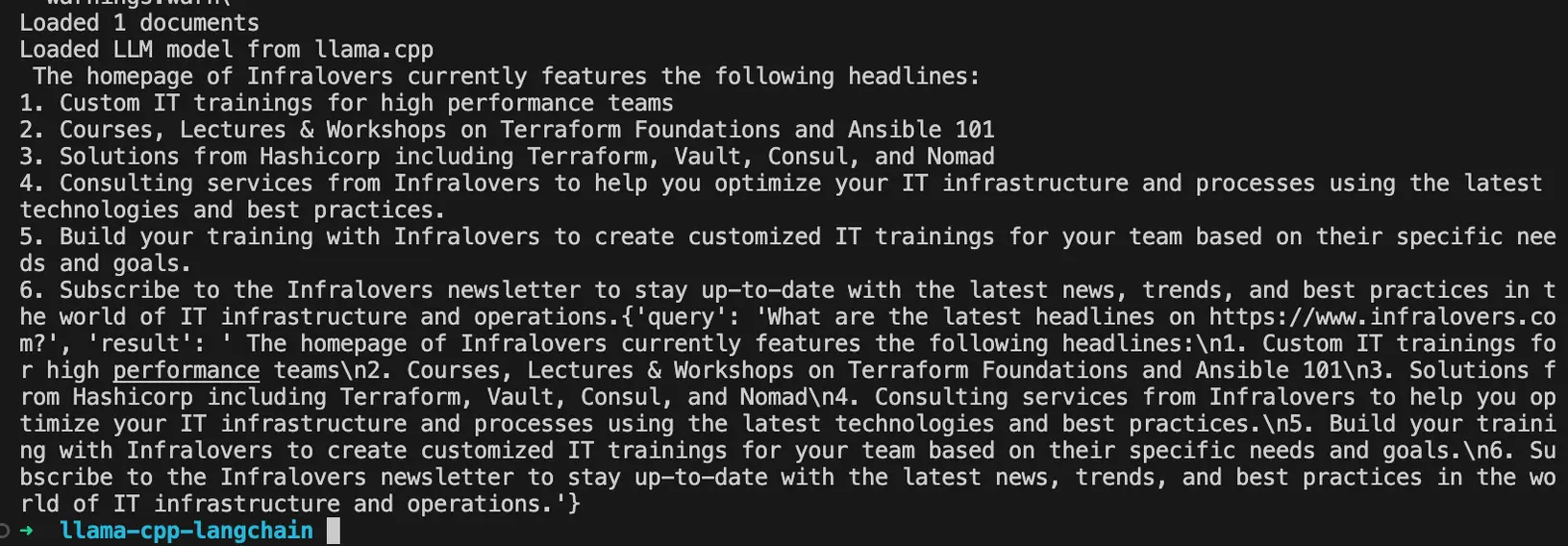
31 print(f"Split into {len(all_splits)} chunks")
32
33 # Embed the documents
34 embed_model_id = 'sentence-transformers/all-MiniLM-L6-v2'
35 device = 'cuda' if torch.cuda.is_available() else 'cpu'
36 embed_model = HuggingFaceEmbeddings(
37 model_name=embed_model_id,
38 model_kwargs={'device': device},
39 encode_kwargs={'device': device, 'batch_size': 32}
40 )
41
42 # Create a vector database using embeddings
43 vectorstore = Chroma.from_documents(documents=all_splits, embedding=embed_model)
44
45 # Print the number of documents
46 print(f"Loaded {len(data)} documents")
47
48 # Load the LlamaCpp LLM
49 llm = LlamaCpp(
50 model_path="/path/to/modelfile",
51 n_batch=512,
52 n_ctx=2048,
53 f16_kv=True,
54 temperature=0.5,
55 callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
56 verbose=False,
57 )
58 print(f"Loaded LLM model from llama.cpp")
59
60 # Create the QA chain
61 qa_chain = RetrievalQA.from_chain_type(
62 llm,
63 retriever=vectorstore.as_retriever()
64 )
65
66 # Ask a question
67 question = f"What are the latest headlines on {url}?"
68 result = qa_chain.invoke({"query": question})
69 print(result)
70
71if __name__ == "__main__":
72 main()
Natürlich ist das LangChain-Framework zu weit mehr in der Lage. Die API-Referenzen von Ollama und Llama.cpp bieten sich an, um einen detaillierteren Einblick in die Möglichkeiten lokaler KI-Anwendungen zu erhalten.
Der effektive Einsatz lokaler Large Language Models erfordert ein gewisses Verständnis sowohl ihrer technischen Spezifikationen als auch der erforderlichen Hardware. Dieser Abschnitt behandelt die technischen Aspekte des Einsatzes lokaler LLMs, einschließlich verschiedener Modellspezifikationen und Leistungsbenchmarks. Darüber hinaus werden wir die empfohlenen Hardware-Anforderungen umreißen und Tipps zur Optimierung der Hardware-Nutzung bereitstellen, um einen effizienten und effektiven KI-Betrieb zu gewährleisten.
Lokale LLMs, wie die von Ollama und Llama.cpp, haben je nach ihren Parametern unterschiedliche Anforderungen (z. B. die Anzahl der Parameter in Milliarden). Die Leistung und Effizienz dieser Modelle wird in hohem Maße von der Hardware beeinflusst, auf der sie laufen, insbesondere im Hinblick auf CPU-, Speicher- und GPU-Kapazitäten.
Die Hardwareanforderungen für die Ausführung von LLMs hängen von der Modellgröße ab und davon, ob die Inferenz auf einer CPU oder einem Grafikprozessor durchgeführt wird:
CPU-Anforderungen:
GPU-Anforderungen:
Apple-Silicon:
Generell werden Grafikprozessoren für die Ausführung von großen Sprachmodellen bevorzugt, da sie mehrere Operationen gleichzeitig ausführen können, was KI-Aufgaben im Vergleich zu CPUs erheblich beschleunigt, die zwar auch in der Lage sind, lokale KI-Aufgaben auszuführen, aber tendenziell weniger optimiert und daher langsamer für KI-Anwendungen sind. Apple Silicon mit seiner integrierten Architektur, die CPU, Grafikprozessor und neuronale Verarbeitungseinheiten kombiniert, zeichnet sich bei vielen KI-Aufgaben durch eine effiziente Verwaltung von Energie und Leistung aus, was es für KI-Modelle im mittleren Leistungsbereich sehr effektiv macht.
Die Quantisierung ist eine Technik, bei der die Genauigkeit der Zahlen, die zur Darstellung der Modellparameter verwendet werden, verringert wird, wodurch die Modellgröße und die Rechenlast effektiv reduziert werden. Dies kann die Inferenz erheblich beschleunigen und den Speicherbedarf reduzieren, ohne die Modellleistung wesentlich zu beeinträchtigen.
Die 4-Bit- und 8-Bit-Quantisierung sind gängige Quantisierungsstufen, die einen guten Kompromiss zwischen der Reduzierung der Modellgröße und der Beibehaltung der Leistung bieten. Beispielsweise kann die Quantisierung eines 7B-Modells von 16-Bit- auf 4-Bit-Präzision die Modellgröße um den Faktor vier reduzieren, so dass es auch auf weniger leistungsfähiger Hardware ausgeführt werden kann.
Um effiziente und effektive KI-Operationen zu gewährleisten, stellen wir die folgenden Tipps zur Optimierung der Hardware-Nutzung bereit:
Hinweis: Es gibt keine ROCm-Unterstützung für MacOS.
Hinweis: Wenn Ollama verwendet wird, ist zu beachten, dass es keine offizielle Unterstützung für die GPU-Nutzung für Intel-basierte Macs gibt.
Indem wir diese technischen Spezifikationen und Hardwareanforderungen verstehen und umsetzen, können wir sicherstellen, dass unsere lokalen LLM-Einsätze sowohl effizient als auch effektiv sind und die notwendige Rechenleistung für die reibungslose und zuverlässige Bewältigung komplexer KI-Aufgaben geboten ist.
Die Erforschung lokaler Large Language Models wie Ollama und Llama.cpp hat gezeigt, dass sie ein erhebliches Potenzial für die Verbesserung der Fähigkeiten von KI-Anwendungen direkt auf persönlicher und organisatorischer Hardware haben. Diese Modelle stellen eine datenschutzfreundliche, sichere und effiziente Alternative zu Cloud-basierter KI dar und bieten eine umfassende Kontrolle über die Daten und betriebliche Unabhängigkeit.
Ollama und Llama.cpp bringen jeweils einzigartige Stärken mit sich. Ollama ist besonders benutzerfreundlich und automatisiert viele Aspekte der Modellverwaltung und -bereitstellung, was es ideal für diejenigen macht, die Komfort und Effizienz im Betrieb suchen. Im Gegensatz dazu bietet Llama.cpp eine detailliertere Kontrolle über die KI-Modelle, was Benutzer anspricht, die Wert auf detaillierte Anpassungen und tiefes technisches Engagement legen.
Da sich die technologische Landschaft weiter entwickelt, ist zu erwarten, dass die Bedeutung lokaler LLMs aufgrund der steigenden Anforderungen an den Datenschutz, geringere Latenzzeiten und eine geringere Abhängigkeit von einer kontinuierlichen Internetverbindung zunehmen wird. Die Anpassungsfähigkeit dieser Modelle an eine Reihe von Hardwarekonfigurationen in Verbindung mit Fortschritten bei Quantisierungs- und Hardware-Optimierungstechniken verspricht, ihre Anwendbarkeit und Effektivität zu erweitern.
Bleiben Sie auf dem Laufenden mit unserem Blog, um weitere Updates zu den neuesten Tools und Technologien zu erhalten. Wir bei Infralovers sind bestrebt, immer auf dem neuesten Stand der Technik zu sein.
2.500 API-Endpoints. Jeden einzelnen als MCP-Tool exponiert, das wären laut Cloudflare 1,17 Millionen Tokens allein für die Tool-Definitionen, bevor der Agent
Jedes Nomad-Tutorial, das Sie online finden, verwendet den docker-Treiber. Das ist verstaendlich — Container sind portabel, Images buendeln alles, und Docker
In unserem vorherigen Beitrag ueber HashiCorp Nomad und Vault: Dynamic Secrets haben wir den gesamten Lebenszyklus des Secrets Managements fuer eine Python
In den letzten zwei Wochen haben wir drei Mesh-VPN-Lösungen einzeln vorgestellt: NetBird, Tailscale und Headscale. Drei Posts, drei Produkte, eine Frage blieb
In Post 2 dieser Serie haben wir Tailscale als UX-Goldstandard im Mesh-VPN-Segment vorgestellt. Mit einem ehrlichen Caveat: Die Control-Plane ist proprietär,
Sie interessieren sich für unsere Trainings oder haben einfach eine Frage, die beantwortet werden muss? Sie können uns jederzeit kontaktieren! Wir werden unser Bestes tun, um alle Ihre Fragen zu beantworten.
Hier kontaktieren
