

Hol Dir Deine Daten zurück: Warum europäische Cloud-Dienste die Zukunft sind
In der Welt des Cloud Computing ist die Abhängigkeit von US-amerikanischen Cloud-Diensten zu einem wichtigen Diskussionsthema geworden. Ich beobachte bei

In einer Zeit, in der Daten zunehmend zum Rückgrat vieler Branchen werden, ist der Bedarf an effizienter Datenverwaltung und -orchestrierung so groß wie nie zuvor. Hier kommt Kestra ins Spiel, eine leistungsstarke, deklarative Plattform zur Datenorchestrierung, die sich dadurch auszeichnet, dass sie es Unternehmen ermöglicht, Datenflüsse mit Leichtigkeit zu entwerfen, auszuführen und zu überwachen. Mit seinem einzigartigen Ansatz zur Verwaltung komplexer Daten-Workflows durch einfachen Code und Automatisierung revolutioniert Kestra die Art und Weise, wie Unternehmen mit ihren Daten umgehen, macht Prozesse effizienter und verringert die Wahrscheinlichkeit von menschlichen Fehlern. Die Bedeutung eines solchen Tools in der heutigen datengesteuerten Umgebung kann nicht hoch genug eingeschätzt werden, da es eine robuste Lösung für die Herausforderungen der Datenintegration, -verarbeitung und -verteilung bietet.
In diesem Artikel wird erläutert, was Kestra ist und welche Bedeutung es im Bereich der Datenorchestrierung hat. Er führt den Leser durch die ersten Schritte mit Kestra und veranschaulicht, wie die Funktionen zur Erstellung und Verwaltung von Datenflüssen effektiv genutzt werden können. Darüber hinaus werden wir untersuchen, wie die Fähigkeiten von Kestra mit Plugins erweitert werden können, um einen Einblick zu geben, wie die Plattform auf spezifische Bedürfnisse zugeschnitten werden kann. Am Ende werden die Leser ein umfassendes Verständnis der Leistungsfähigkeit von Kestra haben, einschließlich seines Potenzials, die Datenorchestrierung mit seinen Blaupausen für den Erfolg in jeder datenzentrierten Organisation zu verändern.
Kestra ist eine quelloffene, unbegrenzt skalierbare Orchestrierungsplattform, die es Ingenieuren ermöglicht, geschäftskritische Workflows deklarativ im Code zu verwalten. Sie lässt sich in eine Vielzahl von Datenquellen und Tools integrieren und ermöglicht die nahtlose Anbindung von Workflows an bestehende Data Stacks, einschließlich gängiger Datenbanken, Dateiformate, APIs und mehr. Die Plattform ist für die Abwicklung komplexer Daten-Workflows über eine benutzerfreundliche Oberfläche konzipiert und bietet leistungsstarke Funktionen, die die Erstellung und Verwaltung dieser Workflows vereinfachen.
Kestra unterstützt sowohl geplante als auch ereignisgesteuerte Datenpipelines, so dass es mühelos möglich ist, Workflows so zu konfigurieren, dass sie nach einem Zeitplan ablaufen, auf ereignisbasierte Auslöser reagieren oder über Webhooks und APIs funktionieren. Dank des deklarativen Charakters können Benutzer Workflows im Code verwalten und so die Best Practices von Infrastructure as Code (IaC) fördern. Dieser Ansatz verbessert nicht nur die Reproduzierbarkeit von Prozessen, sondern erleichtert auch die Integration mit bestehenden CI/CD-Prozessen und Versionskontrollsystemen wie Git.
Kestra bietet eine Reihe von Funktionen zur Optimierung der Workflow-Ausführung. Dazu gehören erweiterte Einstellungen für Wiederholungen, Timeouts und Fehlerbehandlung, um einen reibungslosen Betrieb zu gewährleisten. Das robuste Plugin-System der Plattform und Hunderte von eingebauten Plugins, gekoppelt mit einem eingebetteten Code-Editor, der Git- und Terraform-Integrationen unterstützt, bieten umfangreiche Anpassungs- und Skalierungsoptionen. Die Benutzer können die Workflow-Leistung in Echtzeit überwachen, Engpässe erkennen und die Geschwindigkeit und Effizienz optimieren - alles über eine übersichtliche und leicht zugängliche Web-UI.
Als universeller Open-Source-Orchestrator fördert Kestra eine wachsende Community, in der Benutzer zur Entwicklung beitragen, Erfahrungen austauschen und Unterstützung suchen können. Die offene Architektur der Plattform bietet grenzenlose Möglichkeiten und fördert Beiträge und Verbesserungen von Entwicklern weltweit. Community-Mitglieder können auf eine Vielzahl von Ressourcen zugreifen, einschließlich eines Leitfadens für Mitwirkende und eines Leitfadens für Plugin-Entwickler, die ihnen helfen, die Fähigkeiten von Kestra zu erweitern.
Um unsere Reise mit Kestra zu beginnen, folgen wir zunächst dem Quickstart Guide, der detaillierte Anweisungen zur Installation von Kestra und zur Einrichtung unseres ersten Workflows enthält. Kestra kann in verschiedenen Umgebungen installiert werden, egal ob wir Docker für ein schnelles Setup oder eine skalierbarere Lösung wie Kubernetes mit einem Helm-Chart bevorzugen. Für diejenigen, die Kestra in Cloud-Umgebungen integrieren möchten, gibt es Optionen wie AWS EKS mit PostgreSQL RDS und S3-Speicher, GCP GKE mit CloudSQL oder Azure AKS mit PostgreSQL und Blob Storage.
In diesem Blog-Beitrag werden wir Kestra mit Hilfe der mitgelieferten Docker-Installationsanleitung installieren. Um der Anleitung folgen zu können, müssen wir Docker in unserer Umgebung installiert haben.
1docker run --pull=always --rm -it -p 8080:8080 --user=root \
2 -v /var/run/docker.sock:/var/run/docker.sock \
3 -v /tmp:/tmp kestra/kestra:latest-full server local
Nach der Installation können wir auf die umfangreiche Web-Benutzeroberfläche von Kestra standardmäßig über Port 8080 zugreifen, die normalerweise unter http://localhost:8080 verfügbar ist.
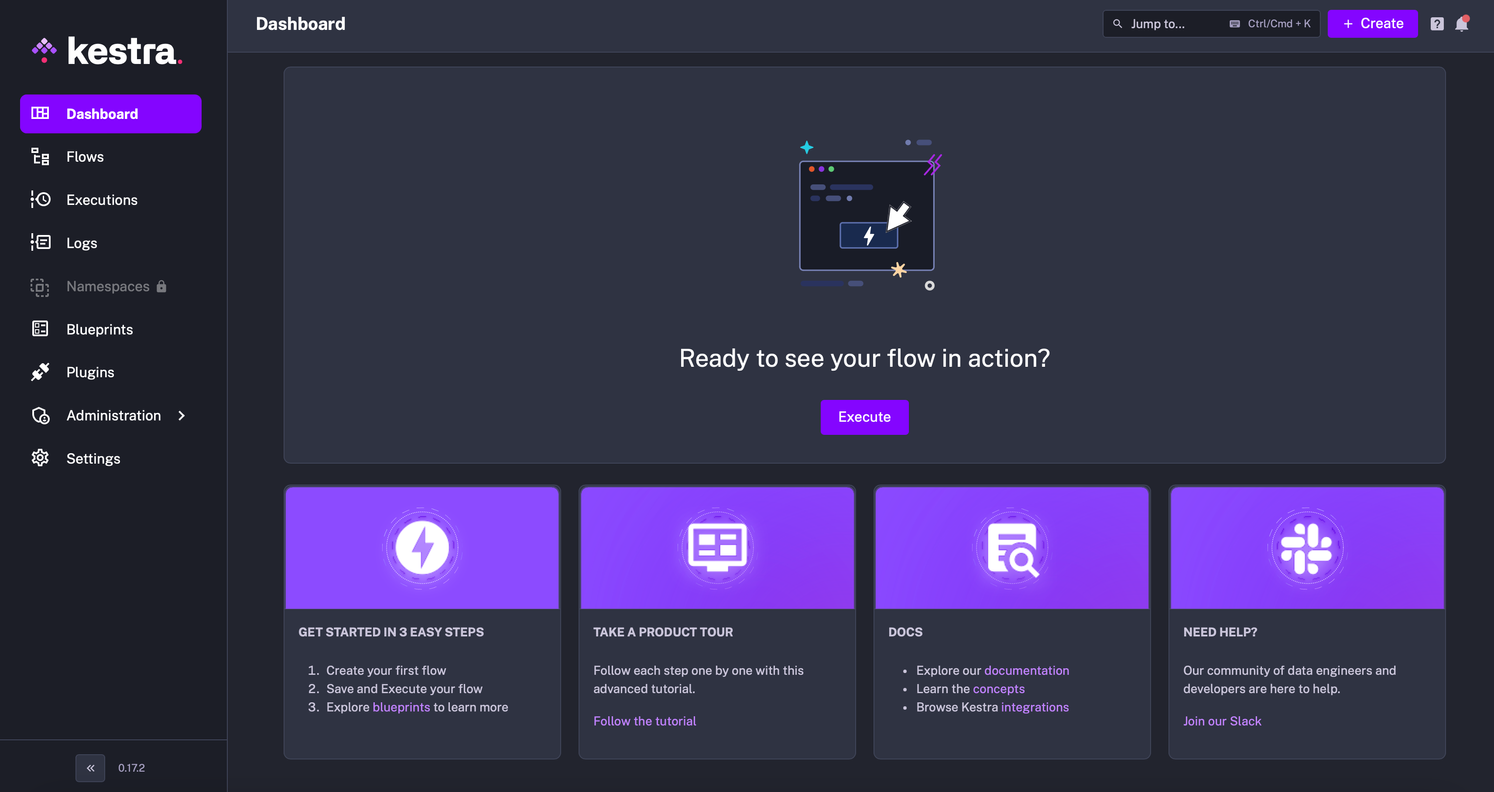
Nach der Installation können wir Kestra in einem Docker-Container starten und so ganz einfach unseren ersten Workflow erstellen. Die Plattform unterstützt Workflows, die bedarfs- oder ereignisgesteuert sind oder auf einem regelmäßigen Zeitplan basieren. Man kann damit beginnen, einen einfachen "Hello world"-Workflow zu erstellen, um sich mit den grundlegenden Konzepten wie Namespaces, Aufgaben, Eingaben und Auslösern vertraut zu machen. Im weiteren Verlauf kann man sich mit der parallelen Ausführung von Aufgaben, der Verwaltung von Fehlern mit automatischen Wiederholungsversuchen und der Integration von benutzerdefinierten Skripten oder Microservices beschäftigen. Die über die Kestra-Benutzeroberfläche verfügbare geführte Tour bietet einen [Schritt-für-Schritt-Walkthrough] (https://kestra.io/docs/getting-started/ui), der das Verständnis für die Erstellung und effektive Ausführung von Abläufen verbessert.
Ein einfacher Workflow, mit dem man beginnen kann, könnte wie folgt aussehen:
1id: myflow
2namespace: company.myteam
3description: Save and Execute the flow
4
5labels:
6 env: dev
7 project: myproject
8
9inputs:
10 - id: payload
11 type: JSON
12 defaults: |-
13 [{"name": "kestra", "rating": "best in class"}]
14
15tasks:
16 - id: send_data
17 type: io.kestra.plugin.core.http.Request
18 uri: https://reqres.in/api/products
19 method: POST
20 contentType: application/json
21 body: "{{ inputs.payload }}"
22
23 - id: print_status
24 type: io.kestra.plugin.core.log.Log
25 message: hello on {{ outputs.send_data.headers.date | first }}
26
27triggers:
28 - id: daily
29 type: io.kestra.plugin.core.trigger.Schedule
30 cron: "0 9 * * *"
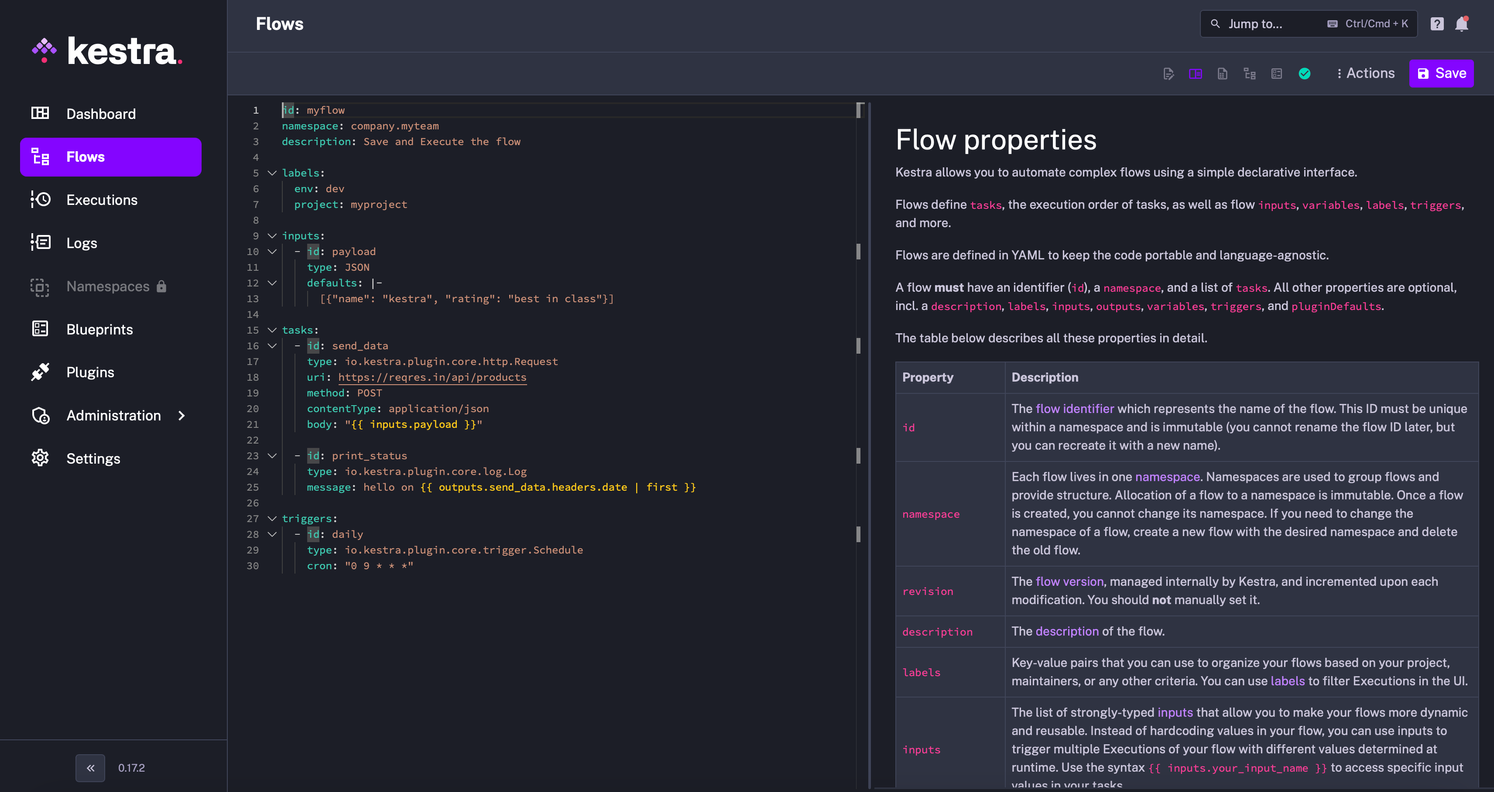
Die Benutzeroberfläche von Kestra ist intuitiv gestaltet und bietet ein zentrales Dashboard, von dem aus Abläufe verwaltet, Ausführungen überwachet und auf Protokolle zugegriffen werden kann. Der Editor-Bildschirm ähnelt modernen Code-Editoren, die mit Funktionen wie Syntax-Hervorhebung und Fehlerprüfung ausgestattet sind und die Erstellung und Änderung von Workflows vereinfachen. Für fortgeschrittene Konfigurationen enthält die Benutzeroberfläche Registerkarten für die Verwaltung von Triggern und Workern sowie für die Anzeige detaillierter Metriken der Aufgabenausführungen. Darüber hinaus bietet die Plattform eine Vielzahl von Blueprints, d. h. vordefinierte Vorlagen, die als Ausgangspunkt für die Erstellung neuer Aufgaben oder Abläufe verwendet werden können.
Das Plugin-System von Kestra ist die Grundlage der Funktionalität und ermöglicht Aufgaben und Auslöser, die mit externen Systemen interagieren und kritische Operationen innerhalb der Datenflüsse durchführen. Die Plattform wird mit über 490 Plugins ausgeliefert, die eine Vielzahl von Kategorien wie Datenbank, Messaging, Scripting, Transformation, Batch Processing, Alerting, Cloud Storage und mehr abdecken. Diese Plugins sind die Bausteine von Kestra's Tasks und Triggern und bieten die notwendigen Werkzeuge für eine effektive Datenorchestrierung.
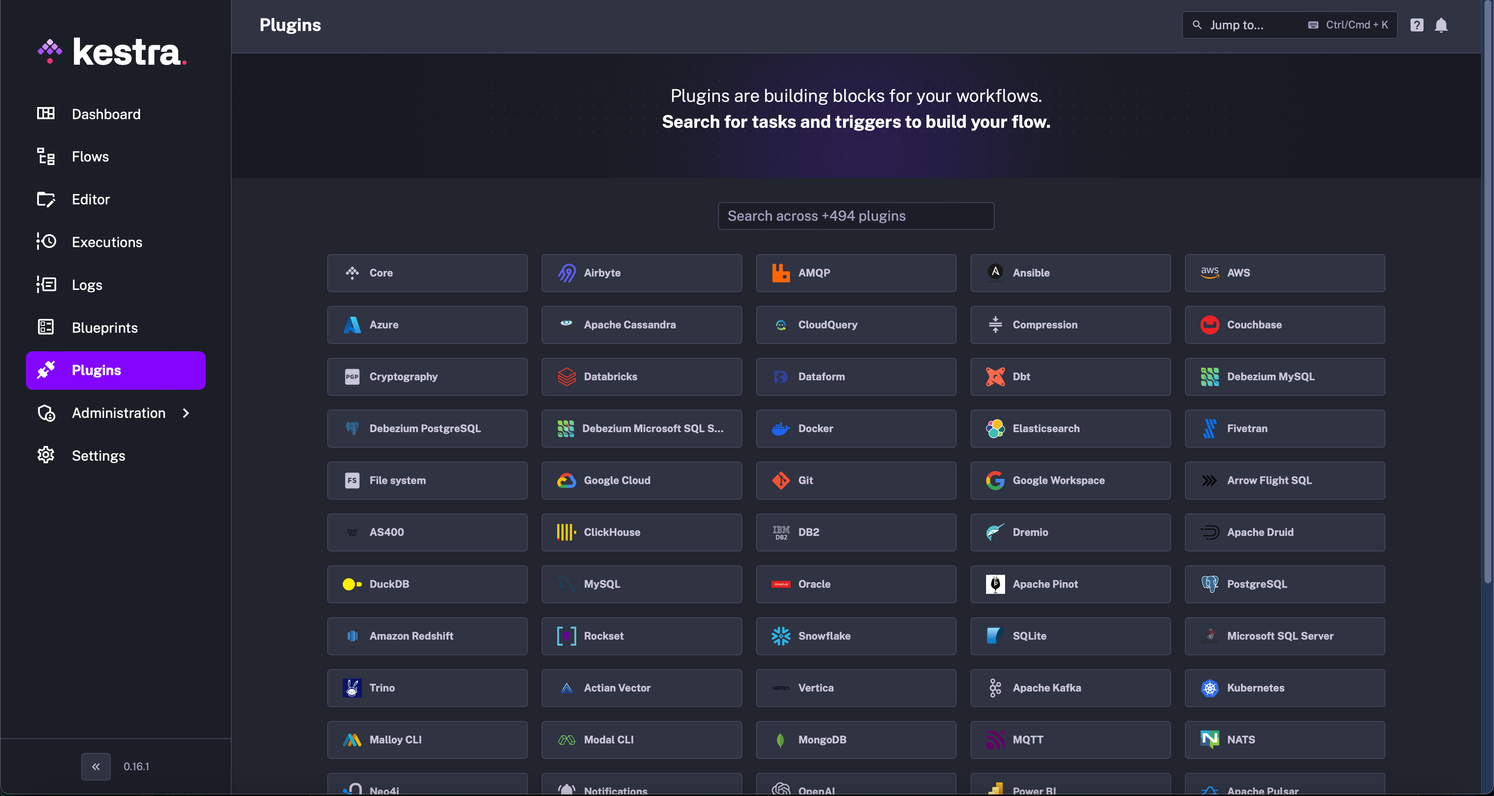
Unter der großen Auswahl an Plugins sind einige der meistgenutzten die für S3, DynamoDB, DBT, Fivetran, Git, DuckDB, Rockset, Spark und PowerBI. Diese Plugins unterstützen eine Reihe von Standardfunktionen, die für moderne Daten-Workflows entscheidend sind, und ermöglichen es den Benutzern, Kestra nahtlos in verschiedene Datensysteme und -tools zu integrieren. Die Flexibilität und der Umfang dieser Plugins stellen sicher, dass Benutzer nahezu jede Datenverwaltungsaufgabe bewältigen können, von einfachen Dateitransformationen bis hin zu komplexer Batch-Verarbeitung und Echtzeit-Dateningestion.
Für Benutzer mit speziellen Anforderungen ermöglicht Kestra die Entwicklung von benutzerdefinierten Plugins. Diese Möglichkeit verbessert nicht nur die Personalisierung, sondern fördert auch eine kollaborative Umgebung, in der die Benutzer zur breiteren Gemeinschaft beitragen können. Wenn sich ein benutzerdefiniertes Plugin als nützlich erweist, werden die Entwickler ermutigt, es mit der Open-Source-Gemeinschaft zu teilen und so das Kestra-Ökosystem weiter zu bereichern. Eine ausführliche Anleitung zur Entwicklung von benutzerdefinierten Plugins finden wir im Plugins Developer Guide, der Anweisungen zum Einrichten von Entwicklungsumgebungen, zum Schreiben von Code und zum Testen von Plugins enthält, um Kompatibilität und Funktionalität sicherzustellen. Dieser Prozess wird durch eine umfassende Dokumentation und den Support der Community unterstützt, so dass er auch für Neulinge in der Plugin-Entwicklung zugänglich ist.
Die Erkundung von Kestra hat gezeigt, dass der innovative Ansatz der deklarativen Datenorchestrierung eine transformative Lösung für die Verwaltung komplexer Daten-Workflows mit beispielloser Effizienz und Flexibilität bietet. Die Fähigkeit der Plattform, sich in eine Vielzahl von Tools und Systemen zu integrieren, zusammen mit der unterstützenden Open-Source-Community und dem robusten Plugin-Ökosystem, positioniert Kestra als ein vielseitiges und potentes Tool für Unternehmen, die ihre Datenoperationen rationalisieren wollen.
Unternehmen, die sich mit der Komplexität von Big Data auseinandersetzen und nach Lösungen suchen, die mit der rasanten Entwicklung von Technologielandschaften Schritt halten können, sind mit Kestra auf der sicheren Seite, wenn es um die zukunftsorientierte Datenorchestrierung geht. Seine Betonung auf Benutzerfreundlichkeit, Skalierbarkeit und Anpassung durch codebasierte Workflows fördert einen proaktiven und effizienten Ansatz für das Datenmanagement.
Einführung in eine moderne Infrastruktur-Bereitstellung.
Kollaborative Infrastruktur-Automatisierung.
Schneller am eigenen Code zusammenarbeiten und mit Git und GitLab Ausliefern.
In der Welt des Cloud Computing ist die Abhängigkeit von US-amerikanischen Cloud-Diensten zu einem wichtigen Diskussionsthema geworden. Ich beobachte bei
Wir bei Infralovers GmbH freuen uns, unser umfassendes Crossplane Training anzukündigen. Als leidenschaftliche Befürworter von Cloud-Native-Technologien sind
Jahresrückblick 2024 und Ausblick auf 2025 bei Infralovers 2024 war für uns ein Jahr voller Innovationen und neuer Lernmöglichkeiten. Wir haben unser
Infrastructure as Code (IaC) hat die Art und Weise, wie wir Cloud-Ressourcen verwalten, revolutioniert, und Terraform hat sich zu einem führenden Tool in diesem
Es ist keine Überraschung, dass künstliche Intelligenz weiterhin die Schlagzeilen beherrscht. Neue Durchbrüche, Tools und Vorschriften prägen die Art und Weise,
Sie interessieren sich für unsere Trainings oder haben einfach eine Frage, die beantwortet werden muss? Sie können uns jederzeit kontaktieren! Wir werden unser Bestes tun, um alle Ihre Fragen zu beantworten.
Hier kontaktieren
