

OpenBao Compatibility Check: Running Vault + Nomad Patterns with Minimal Changes
If you already run Nomad + Vault patterns in production, the first question about OpenBao is simple: will our existing workloads still run without a rewrite? In

In the previous parts (part one and part two) of this blog series, we explored the challenges facing DevOps today, how AI can address them, and how to build powerful AI applications using frameworks like LangChain. Now, in this final part, we'll look at infrastructure options for hosting AI applications, optimising their performance, enabling guardrails for secure interaction, and using AI agents to automate complex workflows.
When deploying AI applications, one of the first decisions is choosing the hosting option for our language model. There are two main approaches: cloud-based models and self-hosted models.
Cloud-based models are provided by companies like OpenAI, Anthropic, Azure AI, and even more cloud providers. These services are popular for their ease of use and scalability.
Self-hosting involves running the model on our own infrastructure using tools like Ollama, Llama.cpp, or LM Studio.
Inference speed refers to how quickly a model processes and generates responses. Several factors influence this:
If the application requires different models for various tasks, language model proxying can help. This technique intelligently routes requests to specific models based on predefined factors or tasks.
LiteLLM is an open-source framework designed to simplify working with multiple language models. It provides a standardized API to call over 100 different LLMs, such as OpenAI, Anthropic, Google Gemini, and Hugging Face.
Here’s how we can use LiteLLM to manage multiple LLMs in a single application:
1import streamlit as st
2from litellm import completion
3
4st.title("Multi-Model Chat")
5
6# LiteLLM Completion function to get model response
7def get_model_response(model_name: str, prompt: str) -> str:
8 response = completion(model=model_name, messages=[{"role": "user", "content": prompt}])
9 return response.choices[0].message.content
10
11# Streamlit UI Selection for model
12model_option = st.selectbox("Choose a language model:", ("gpt-3.5-turbo", "ollama/llama2", "gpt-4o"))
13
14# Chat history session state
15if 'chat_history' not in st.session_state:
16 st.session_state['chat_history'] = []
17
18user_input = st.text_input("You:")
19
20# Send user input and get model response
21if st.button("Send") and user_input:
22 st.session_state['chat_history'].append({"role": "user", "content": user_input})
23 with st.spinner("Thinking..."):
24 response = get_model_response(model_name=model_option, prompt=user_input)
25 st.session_state['chat_history'].append({"role": "model", "content": response})
26
27for message in reversed(st.session_state['chat_history']):
28 st.write(f"{message['role'].capitalize()}: {message['content']}")
In this example, we create a simple chat application that allows users to choose from different language models. The get_model_response function sends the user input to the selected model and returns the response. The chat_history session state retains the conversation history, and the Streamlit interface displays the chat messages in an interactive web UI.

Once our AI application is running, monitoring its performance is critical to ensure reliability and efficiency.
We can use AI-powered tools like Grafana or BigPanda for effective monitoring and analysis.
Running LLM applications can be expensive, so understanding and managing costs is essential.

Public-facing LLM applications come with unique security challenges.
AI agents go beyond generating text — they perform tasks autonomously, enabling complex, multi-step workflows. Let’s explore their key characteristics and how to build them.
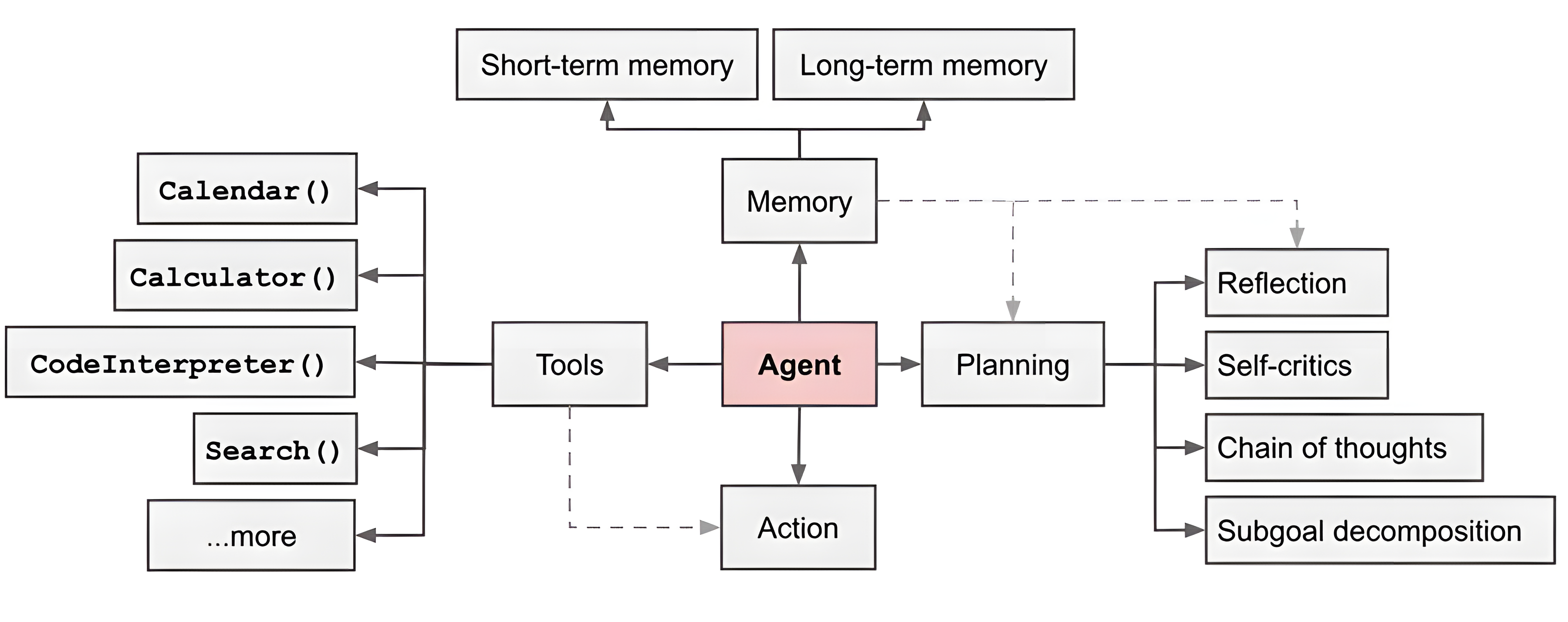
An AI agent consists of several components that work together to perform tasks effectively:
LangGraph is also a component of the LangChain ecosystem that provides a "visual" interface for designing and managing agent workflows. It simplifies the process of connecting different components and orchestrating complex tasks.
This agent performs web research and summarizes the results.
1from langchain.chat_models import ChatOpenAI
2from langchain.tools import DuckDuckGoSearchRun
3from langgraph.graph import StateGraph, END
4from typing import TypedDict, Annotated, List
5import operator
6
7# Initialize models and tools
8research_model = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.7)
9summary_model = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.3)
10search_tool = DuckDuckGoSearchRun()
11
12# Define graph state structure
13class ResearchState(TypedDict):
14 query: str
15 research_results: Annotated[List[str], operator.add]
16 summary: str
17
18graph = StateGraph(ResearchState)
19
20# Define agent functions
21def research_agent(state):
22 query = state["query"]
23 search_result = search_tool.run(query)
24 return {"research_results": [search_result]}
25
26def summarization_agent(state):
27 research_results = state["research_results"]
28 summary_prompt = f"Summarize the following research results:\n{research_results}"
29 summary = summary_model.predict(summary_prompt)
30 return {"summary": summary}
31
32# Build the graph
33graph.add_node("research", research_agent)
34graph.add_node("summarize", summarization_agent)
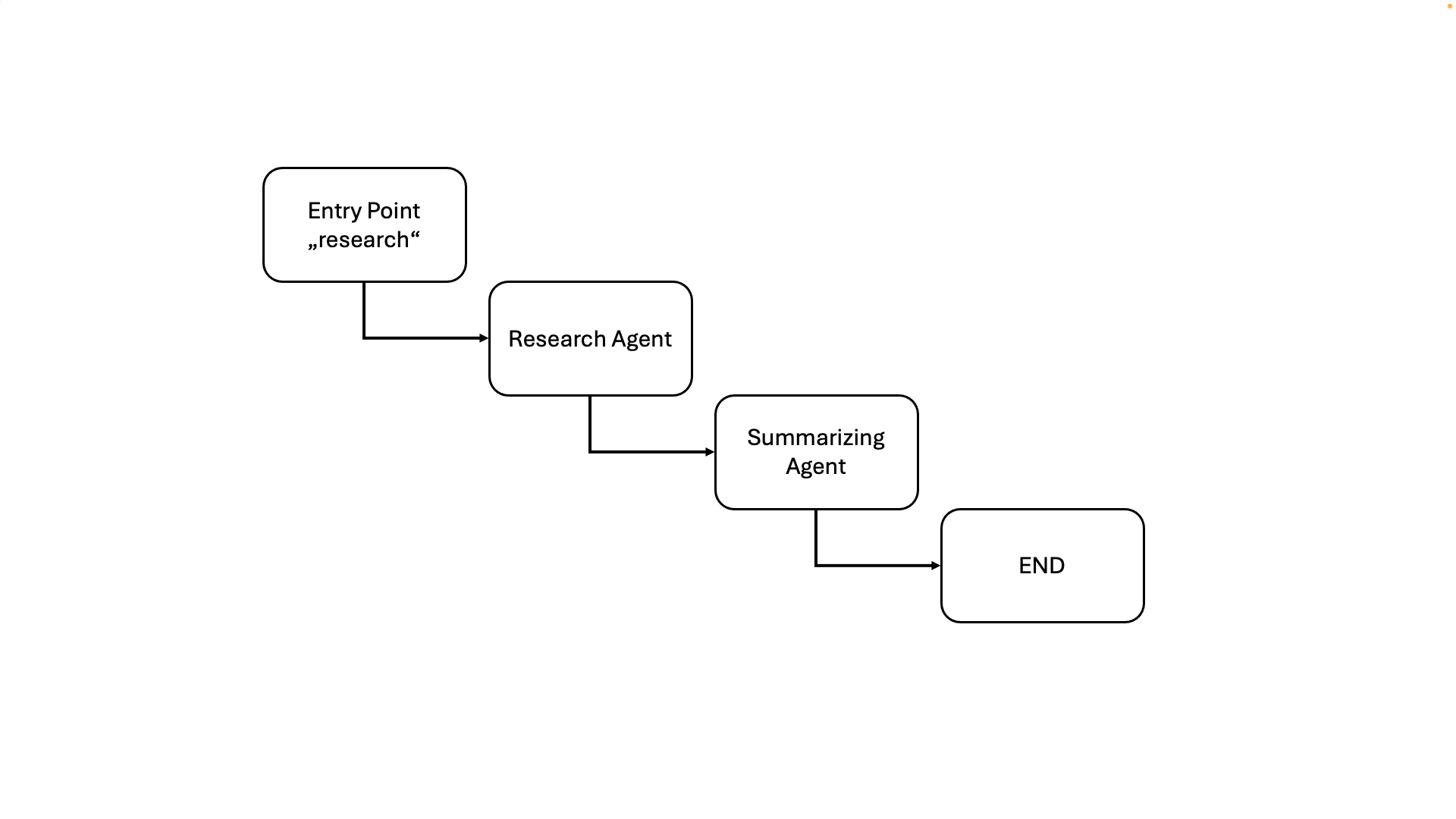
35graph.set_entry_point("research")
36graph.add_edge("research", "summarize")
37graph.add_edge("summarize", END)
38
39# Compile and run
40app = graph.compile()
41
42def run_research(query):
43 result = app.invoke({"query": query, "research_results": [], "summary": ""})
44 return result["summary"]
45
46# Example usage
47research_topic = "Latest advancements in AI"
48summary = run_research(research_topic)
49print(f"Research Summary on '{research_topic}':\n{summary}")
In this example, we define a research agent that performs a web search on a given topic and summarizes the results. The agent uses LangGraph to create a state machine that guides the workflow through research and summarization steps. The run_research function initiates the agent with a research query and returns the final summary.
This is what the visual representation of this simple agent workflow would look like:
In this final part of our blog series, we explored the critical aspects of deploying and managing AI applications for DevOps engineers. From hosting options and performance optimization to monitoring, cost management, and security, we covered the essential considerations for building reliable and efficient AI-powered systems. Additionally, we talked about AI agents, showcasing their ability to automate complex workflows and adapt to dynamic environments.
This blog series explored how AI is transforming DevOps, from addressing challenges to building and deploying advanced AI applications. Let's quickly recap the key takeaways:
Thank you for joining us on this journey! Stay curious and feel free to reach out if you have any questions or need further guidance.
Again, if you're hungry for more details, make sure to check out our video-recordings of our latest AI for Devops Engineers Workshop on YouTube:
If you already run Nomad + Vault patterns in production, the first question about OpenBao is simple: will our existing workloads still run without a rewrite? In
When we published our HashiCorp Nomad and Vault: Dynamic Secrets post, the demo ran exclusively as a Python Flask application. Since then, the repository has
The previous article, Tool-Surface Compression, was about getting external functionality, entire APIs and systems, into the agent as token-efficiently as
2,500 API endpoints. Expose every one of them as an MCP tool and you get, according to Cloudflare, 1.17 million tokens for tool definitions alone, before the
Every Nomad tutorial you will find online uses the docker driver. That makes sense — containers are portable, images bundle everything, and Docker is
You are interested in our courses or you simply have a question that needs answering? You can contact us at anytime! We will do our best to answer all your questions.
Contact us