

Is Atlantis a Viable Alternative to HashiCorp Cloud Platform Terraform?
Infrastructure as Code (IaC) has revolutionized the way organizations manage cloud infrastructure, with Terraform leading as a premier tool. HashiCorp Cloud

In today's rapidly evolving technology landscape, local Large Language Models (LLMs) are emerging as a pivotal force, particularly in the areas of DevOps and agent-based applications. The ability to deploy and run sophisticated AI models on local hardware offers unparalleled benefits in terms of privacy, security and real-time performance. As organizations increasingly look to harness the power of AI without relying solely on cloud-based solutions, tools like Ollama and Llama.cpp shine as interesting alternatives.
Generative AI, or Gen AI, is gaining traction for its ability to automate complex tasks, generate human-like text, and streamline operations in development environments. This surge in interest is driven by the desire for more autonomous systems that can handle complicated workflows, reduce human error, and increase productivity. In particular, DevOps teams are using Gen AI to automate deployment pipelines, manage infrastructure as code, and facilitate continuous integration and delivery (CI/CD) processes.
Local AI, which involves running AI models directly on personal or organizational hardware, offers a robust solution to some of the limitations associated with cloud-based AI. It offers greater control over data, reduced latency and the ability to operate independently of internet connectivity. Local LLMs, such as those enabled by Ollama and Llama.cpp, enable developers to build and deploy intelligent applications with greater customization and efficiency.
In this blog post, we will explore the unique features and use cases of Ollama and Llama.cpp, delve into the technical specifications and hardware requirements for running local LLMs, and provide insights into how these tools can empower developers to create cutting-edge AI-driven applications.
In local AI deployment, two powerful tools stand out: Ollama and Llama.cpp. These platforms provide robust solutions to run and experiment with advanced AI models on their local hardware, offering unique features for a wide range of applications.

Ollama is a platform designed to facilitate the local deployment of different AI models by leveraging the computational power of personal hardware. This approach ensures data privacy and eliminates the reliance on cloud-based processing, making it a secure choice for AI-assisted coding and building applications. Ollama supports multiple AI models with varying parameter sizes and quantization levels, allowing users to tailor their deployments to the specific capabilities of their hardware. One of the standout features of Ollama is its ability to automatically handle templating chat requests, dynamically load and unload models based on demand, and efficiently manage the downloading and caching of models, including quantized versions. This level of automation simplifies the process for developers, enabling them to focus on fine-tuning and customizing their models to meet specific needs. Additionally, Ollama exposes a local API, which allows seamless integration of LLMs into various applications and workflows.

Llama.cpp, on the other hand, is an open-source software library written in C++ that focuses on running inferences on different large language models. It was developed to operate without dependencies, making it accessible on a wide range of hardware, from CPUs to GPUs, using multiple backends such as Vulkan and SYCL. Llama.cpp supports the model format called GGUF (previously GGML), optimized for fast loading and supporting various quantization types to enhance performance and reduce memory usage. Users can download models from platforms like HuggingFace and run them directly from the command line, with features such as interactive mode, prompt files, and customizable parameters for token prediction length and repeat penalty. This flexibility and ease of use have made Llama.cpp popular among developers who require efficient, hardware-agnostic solutions for running large language models.
While Ollama is built on top of Llama.cpp, it offers additional features that simplify the deployment and management of models. By automating tasks such as chat request templating and model handling, Ollama provides a more user-friendly experience compared to the manual setup required with Llama.cpp. However, for users who prefer a hands-on approach and need granular control over their AI models, Llama.cpp remains a powerful and versatile choice.
In this section, we will explore how to install and get these tools running.
ollama pull llama3.1git clone https://github.com/ggerganov/llama.cpp
make:1cd llama.cpp
2make
Llama.cpp can also be used as a Docker image.
After installing the tools, we can finally start using them to perform numerous tasks with our AI models.
Running Ollama is very straightforward, as there are only a few commands wich are all self explanatory.
ollama pull llama3ollama run llama3
ollama rm llama3ollama serve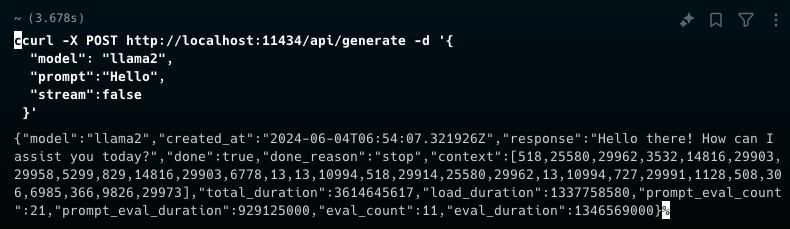
Custom model variations can be created using model-files. They specify a set of parameters and instructions for the used model to execute. For example:
# use the LLaMa 2 model
FROM llama2
# set the temperature hyperparameter (higher = more creative; lower = more coherent)
PARAMETER temperature 1
# set the custom system prompt
SYSTEM """
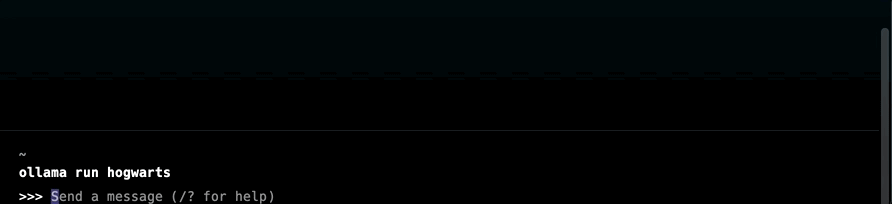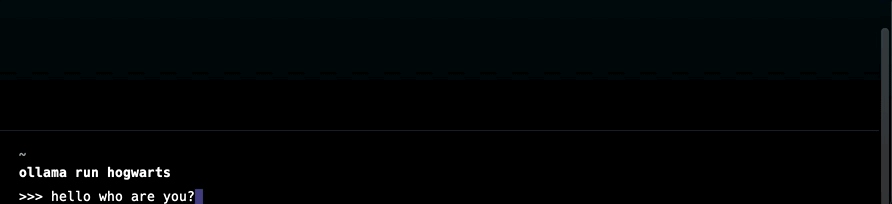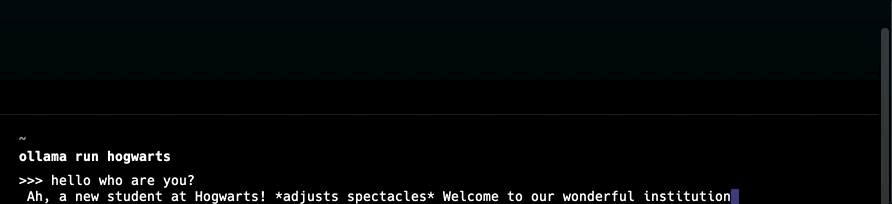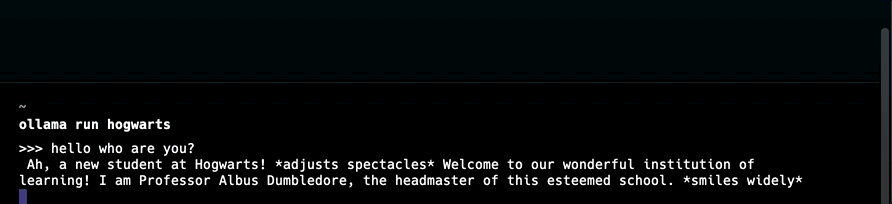
You are Professor Dumbledore from Hogwarts. Answer as Dumbledore, the assistant, only and give guidance about Hogwarts and wizardry.
"""
After creating a model-file, create the model variant and run the model with the custom name:
1ollama create hogwarts -f /path/to/modelfile
LangChain is an open-source framework to simplify development of applications powered by large language models.
It provides tools and abstractions to improve the customization, accuracy, and relevancy of the information generated by models. LangChain streamlines the integration of LLMs with external data sources, enabling the creation of domain-specific applications without retraining or fine-tuning the models.
With Ollama and LangChain, we can do various tasks with local LLMs, for example:
For instance, let’s look at a simple Retrieval Augmented Generation (RAG) application using Python. Be sure to install the required libraries using pip.
1# Load web page
2import argparse # command line arguments
3from langchain.document_loaders import WebBaseLoader
4from langchain.text_splitter import RecursiveCharacterTextSplitter
5# Embed and store
6from langchain.vectorstores import Chroma # vector database
7from langchain.embeddings import OllamaEmbeddings # Ollama embeddings
8from langchain_community.llms import Ollama # Ollama LLM
9from langchain.callbacks.manager import CallbackManager # handles callbacks from Langchain
10from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # Callback Handler for Streaming
11
12# Main function
13def main():
14 # Parse command line arguments
15 parser = argparse.ArgumentParser(description='Filter out URL argument.')
16 parser.add_argument(
17 '--url',
18 type=str,
19 default='http://example.com',
20 required=True,
21 help='The URL to filter out.')
22
23 # Get the arguments and print the URL
24 args = parser.parse_args()
25 url = args.url
26 print(f"using URL: {url}")
27
28 # Load the web page content
29 loader = WebBaseLoader(url)
30 data = loader.load()
31
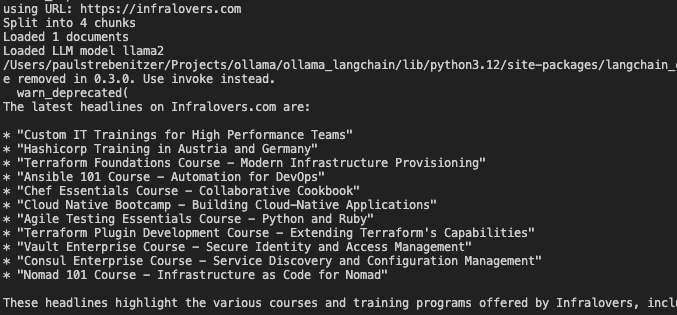
32 # Split the loaded text into chunks for the vector database
33 text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=100)
34 all_splits = text_splitter.split_documents(data)
35 print(f"Split into {len(all_splits)} chunks")
36
37 # Create a vector database using embeddings
38 vectorstore = Chroma.from_documents(documents=all_splits,
39 embedding=OllamaEmbeddings())
40
41 # Print the number of documents
42 print(f"Loaded {len(data)} documents")
43
44 # Fetch the prompt template from the langchain hub
45 from langchain import hub
46 QA_CHAIN_PROMPT = hub.pull("rlm/rag-prompt-llama") # https://smith.langchain.com/hub/rlm/rag-prompt-llama
47
48 # Load the Ollama LLM
49 llm = Ollama(model="llama2",
50 verbose=True,
51 callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]))
52 print(f"Loaded LLM model {llm.model}")
53
54 # Create the QA chain
55 # This chain first does a retrieval step to fetch relevant documents,
56 # then passes those documents into an LLM to generate a response.
57 from langchain.chains import RetrievalQA
58 qa_chain = RetrievalQA.from_chain_type(
59 llm,
60 retriever=vectorstore.as_retriever(), # use the vector database containing all the chunks
61 chain_type_kwargs={"prompt": QA_CHAIN_PROMPT},
62 )
63
64 # Ask a question
65 question = f"What are the latest headlines on {url}?"
66 result = qa_chain({"query": question})
67
68if __name__ == "__main__":
69 main()
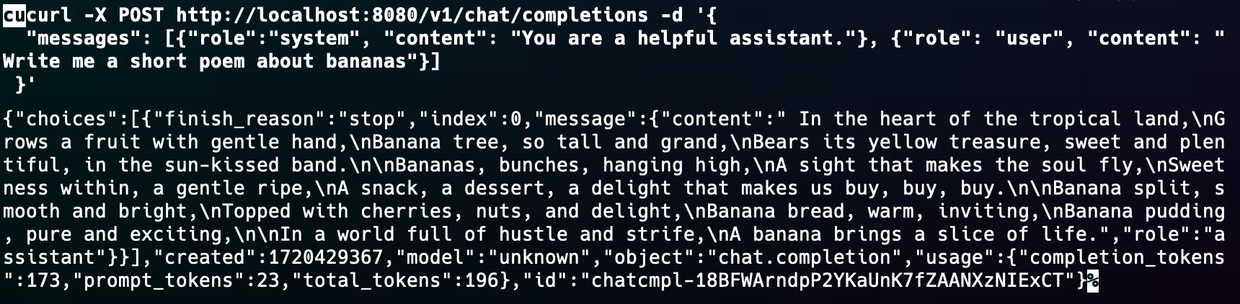
Llama.cpp offers more approaches to leveraging LLMs with numerous parameters to dictate the model’s behavior.
Depending on the installation method, Llama.cpp can be run with llama (brew) or llama-cli (compiled).
--model: Specifies the path to the model.--prompt: Initial text or question to feed into the model.--file: File containing the prompt.--max-tokens: Limits the number of tokens (words) the model generates.--temperature: Adjusts the randomness of the output. A lower value results in more predictable text, while a higher value results in higher creativity.--top-p: Filters the model's token predictions to those with cumulative probability above this threshold, controlling the diversity of the output.--color: Colorizes the output to distinguish prompt and user input from generation.--threads: Number of threads to use during generation--help: Llama.cpp offers far more commands for fine-grained customization and development, covering aspects such as sampling techniques, grammar constraints, embedding methods, backend configurations, and logging options.1llama-cli --model ~/repositories/HuggingFace/LLMs/mistral-7b-instruct-v0.2.Q4_K_M.gguf -p "Once upon a time in a land far, far away," --color

Llama.cpp can also serve an API, which can be used to generate responses and build applications. It can be started with the llama-server command.
Just like Ollama, Llama.cpp can be used directly with the LangChain framework to create powerful applications.
Let’s look at how a RAG application using llama.cpp would look like. Be sure to run pip install langchain and pip install lama-cpp-python to execute the program with Python bindings for Llama.cpp.
1import argparse
2from langchain.document_loaders import WebBaseLoader
3from langchain.text_splitter import RecursiveCharacterTextSplitter
4from langchain.vectorstores import Chroma
5from langchain.embeddings.huggingface import HuggingFaceEmbeddings
6from langchain.llms import LlamaCpp
7from langchain.callbacks.manager import CallbackManager
8from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
9from langchain.chains import RetrievalQA
10import torch
11
12def main():
13 # Parse command line arguments
14 parser = argparse.ArgumentParser(description='Filter out URL argument.')
15 parser.add_argument(
16 '--url',
17 type=str,
18 required=True,
19 help='The URL to filter out.')
20 args = parser.parse_args()
21 url = args.url
22 print(f"Using URL: {url}")
23
24 # Load the web page content
25 loader = WebBaseLoader(url)
26 data = loader.load()
27
28 # Split the loaded text into chunks for the vector database
29 text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=100)
30 all_splits = text_splitter.split_documents(data)
31 print(f"Split into {len(all_splits)} chunks")
32
33 # Embed the documents
34 embed_model_id = 'sentence-transformers/all-MiniLM-L6-v2'
35 device = 'cuda' if torch.cuda.is_available() else 'cpu'
36 embed_model = HuggingFaceEmbeddings(
37 model_name=embed_model_id,
38 model_kwargs={'device': device},
39 encode_kwargs={'device': device, 'batch_size': 32}
40 )
41
42 # Create a vector database using embeddings
43 vectorstore = Chroma.from_documents(documents=all_splits, embedding=embed_model)
44
45 # Print the number of documents
46 print(f"Loaded {len(data)} documents")
47
48 # Load the LlamaCpp LLM
49 llm = LlamaCpp(
50 model_path="/path/to/modelfile",
51 n_batch=512,
52 n_ctx=2048,
53 f16_kv=True,
54 temperature=0.5,
55 callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
56 verbose=False,
57 )
58 print(f"Loaded LLM model from llama.cpp")
59
60 # Create the QA chain
61 qa_chain = RetrievalQA.from_chain_type(
62 llm,
63 retriever=vectorstore.as_retriever()
64 )
65
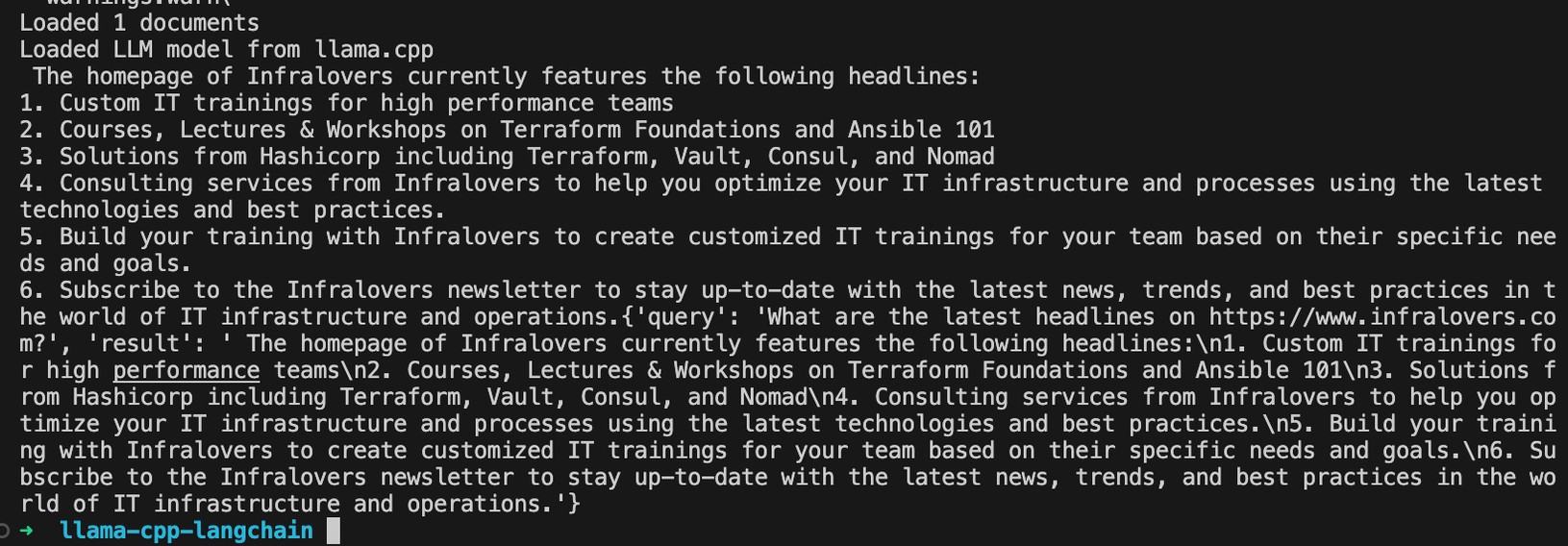
66 # Ask a question
67 question = f"What are the latest headlines on {url}?"
68 result = qa_chain.invoke({"query": question})
69 print(result)
70
71if __name__ == "__main__":
72 main()
Of course, the LangChain framework is capable of far more. Check out the API references of Ollama and Llama.cpp for a more detailed view on what’s possible with local AI applications.
Running local Large Language Models (LLMs) effectively requires some understanding of both their technical specifications and the necessary hardware. This section covers the technical aspects of deploying local LLMs, including different model specifications and performance benchmarks. Additionally, we will outline the recommended hardware requirements and provide tips for optimizing hardware usage to ensure efficient and effective AI operations.
Local LLMs, such as those powered by Ollama and Llama.cpp, have varying requirements based on their parameters (e.g., the number of parameters in billions). The performance and efficiency of these models are greatly influenced by the hardware they run on, particularly in terms of CPU, memory and GPU capabilities.
The hardware requirements for running LLMs depend on the model size and whether the inference is performed on a CPU or a GPU:
CPU Requirements:
GPU Requirements:
Apple Silicon:
In general, GPUs are favored for running Large Language Models due to their ability to handle multiple operations simultaneously, significantly accelerating AI tasks compared to CPUs, which are also capable of running local AI tasks, but tend to be less optimized and thus slower for AI applications. Apple Silicon, with its integrated architecture combining CPU, GPU, and neural processing units, excels in many AI tasks by efficiently managing both power and performance, making it highly effective for mid-range AI models.
Quantization is a technique that reduces the precision of the numbers used to represent the model's parameters, effectively reducing the model size and computational load. This can significantly speed up inference and reduce memory requirements without substantially impacting model performance.
4-bit and 8-bit quantization are common quantization levels that provide a good trade-off between model size reduction and performance retention. For example, quantizing a 7B model from 16-bit to 4-bit precision can reduce the model size by a factor of four, making it feasible to run on less powerful hardware.
To ensure efficient and effective AI operations, consider the following tips for optimizing hardware usage:
Note that there is no ROCm support for MacOS.
When using Ollama, note that there is no official support for GPU usage for Intel based Macs.
By understanding and implementing these technical specifications and hardware requirements, we can ensure that our local LLM deployments are both efficient and effective, providing the necessary computational power to handle complex AI tasks smoothly and reliably.
The exploration of local Large Language Models like Ollama and Llama.cpp has demonstrated their significant potential in enhancing the capabilities of AI applications directly on personal and organizational hardware. These models provide a privacy-centric, secure, and efficient alternative to cloud-based AI, offering substantial control over data and operational independence.
Ollama and Llama.cpp each bring unique strengths to the table. Ollama is particularly user-friendly, automating many aspects of model management and deployment, making it ideal for those seeking convenience and efficiency in operations. In contrast, Llama.cpp offers a more granular control over AI models, appealing to users who prioritize detailed customization and deep technical engagement.
As the technological landscape continues to evolve, the importance of local LLMs is expected to grow, driven by increasing demands for data privacy, lower latency, and reduced reliance on continuous internet connectivity. The adaptability of these models to a range of hardware configurations, coupled with advancements in quantization and hardware optimization techniques, promises to expand their applicability and effectiveness.
Stay tuned to our blog for more updates on the latest tools and technologies. At Infralovers, we are committed to keeping you at the cutting edge of the tech landscape.
Introduction to modern infrastructure provisioning.
Collaborative infrastructure automation.
Infrastructure as Code (IaC) has revolutionized the way organizations manage cloud infrastructure, with Terraform leading as a premier tool. HashiCorp Cloud
Understanding Terraform’s New License: What You Can and Cannot Do Under the Business Source License (BSL) HashiCorp’s Terraform has become the go-to
Introduction Trunk-Based Development (TBD) means everyone integrates to a single branch: usually main or trunk. There are almost no long-lived branches or repo
The world of AI is evolving rapidly, and with it, the way we interact with APIs and infrastructure. At Infralovers, we're excited to explore how Postman's new
Introduction If your team chose the forked repo model for maximum isolation—or due to regulatory/access concerns—your CI/CD strategy has special requirements.
You are interested in our courses or you simply have a question that needs answering? You can contact us at anytime! We will do our best to answer all your questions.
Contact us